Editor’s note: This article is a transcript of a presentation by Don Bruzzone and Paul Shellenberg of Alameda, Calif.-based Bruzzone Research Company to the Advertising Research Foundation’s annual conference in New York in March. Information on contacting the authors can be found at the end of the article.
Good morning, I’m Paul Shellenberg, director of sales at Bruzzone Research, and we are here to describe how you can track the effect of advertising, better, faster, and cheaper online. My function here today is to introduce and pose key questions to our Founder and President Don Bruzzone. I’m hopefully going to keep him on-topic and on-time, without getting fired. Don, can you give us a quick overview of what we are going to be covering?
Don: We are going to be talking about a real breakthrough -- something that doesn’t happen all that often. We are going to talk about how you can track the effect of advertising:
- better through recognition-based research;
- faster - at the speed of e-mail; and
- cheaper because you’re eliminating most of the fieldwork costs by doing it online.
We are going to show that it works by using evidence from parallel studies of Super Bowl commercials. We’re going to be talking about the limitations of online testing, primarily how you allow for the segment of the population that is not online. And, we’re going to be talking about the importance of this breakthrough, being able to do more online research to track the effectiveness of advertising and how important the tracking of advertising is in increasing the profits of your company.
Why it’s better
Paul: Let’s take the first of those topics Don mentioned. Why does the ability to show advertising and see if people recognize it make this type of tracking better?
Don: Because up to now, most ad tracking surveys are conducted by telephone and in telephone surveys you cannot show things to people. When you can point to a specific commercial, or an ad, or a picture of a Web site and say, “Do you remember having seen this before?” you end up getting information that is more accurate, more sensitive, and more discriminating.
You end up identifying two to three times as many ad noticers as you do through the old-fashioned, more expensive phone surveys. In that kind of tracking study the results are less accurate, because when they say they recall your new advertising they may actually be remembering your old advertising or even your competitor’s advertising. When you try to describe the advertising, that adds a little to the accuracy but it ads a lot to the length and cost of the survey.
Recognition-based tracking identifies the people who have been exposed to the advertising - and who didn’t ignore it but actually noticed it - with fewer errors. It capitalizes on one of the great strengths of the human mind: its ability to recognize things it has seen before. It is critical to make the most accurate possible split of the sample into those who actually noticed your advertising and those who either ignored your advertising or were never exposed to it. It gives you the opportunity to see if that first group shows effects that you don’t see in the second group. That is one of the most critical splits you can make in advertising research, and recognition-based tracking is the best way to do it.
One more point: Recognition-based advertising research does not penalize emotional ads. Hugh Zielske’s classic research at FCB showed that recall-based tests penalize emotional advertising. If you do your research based on recall you run the danger of over-emphasizing the effectiveness of message commercials and not making enough use of emotionally-oriented commercials. That is why recognition makes this kind of testing better.1
Why it’s faster
Paul: Okay. The next thing you said was that online makes it faster. Can you tell us more about speed?
Don: The first thing to consider is that everybody is going to be notified and contacted instantly. Within a minute or so, everyone in the sample is sent an invitation. The invitation says, “Click on this URL and you will immediately be connected to the survey site and you can start filling out the questionnaire.”
Secondly, they can all reply simultaneously. Respondents don’t get interviewed one after the other. You will see the benefits immediately because half of all the replies come back the first day or so. But you don’t want to stop as soon as those initial results are in. They are interesting and they are perfectly valid as an indicator of how those who reply rapidly to e-mail invitations answer the questions. But, they end up being largely the “geeks” of the online population. They are the ones who are online more, they see your invitation sooner, and they are more apt to reply faster. To get replies from a more complete cross-section that includes those of us who take a little more time to reply to our e-mail, you need to wait awhile. But not too long. Almost all the replies you’re ever going to get will show up within five days, and that’s what makes online interviewing faster.
Why it’s cheaper
Paul: The title of our presentation indicated that online also makes it cheaper. How does online do that?
Don: The whole process is simpler and more direct. Think about it: You have no fieldwork infrastructure to pay for. You have no interviewers, or people to supervise the interviewers. You have no one to hire the interviewers or supervisors. You don’t have the facilities; you don’t need a phone room; you don’t need the mall interviewing facilities. And, you have the respondents doing all the data entry work. Those are the factors that make online research cheaper.
Limitations
Paul: But aren’t there some limitations to this approach?
Don: Yes. We referred to the big one before: When people are replying online you are not getting replies from the segment of the population that isn’t online. We tested two different methods of meeting that need in the Super Bowl results we’ll be showing in a moment. We are also going to present some evidence showing what happens if you just ignore the offline segment of the population. We have some very interesting evidence on that point.
Another limitation: there is no clean way to draw a pure probability sample of online households. The all-inclusive sampling frame that you need to do that just doesn’t exist. For telephone surveys you can generate numbers at random from the blocks of phone numbers that are known to be in use. For door-to-door interviewing you can select blocks, and dwelling units on that block, at random. But there is nothing like that for the online universe. It is a real problem. We have been testing and experimenting to find the best ways to meet those problems. Watch how we did it in our parallel testing of this year’s Super Bowl commercials.
The evidence that it works
Paul: Sounds great so far, but does it work? What evidence do we have that all this is true?
Don: We have lots of evidence from the Super Bowl. We feel this is a very unique standard for comparisons. And, we certainly agree with the folks at Harris Black when they made the point in a presentation yesterday that there is a continuing need for parallel studies. The best evidence we have on the validity of online research is to have online studies that can be anchored to studies of known validity. We are anchoring to the tracking studies we’ve been doing for nine years now in which we test and track the effectiveness of every Super Bowl commercial. We do it on the basis of recognition and our standard battery of questions by mail showing photo boards.
The phone-recruited online study
The first comparison is with a method we have used quite successfully in the past. Respondents were recruited by telephone by Bernett Research. Bernett called a cross-section of households obtained originally by random-digit dialing, asking if they would participate in a survey of Super Bowl advertising. If the respondent said yes, they were asked if they were online and if we could have their e-mail address. If they said no, we obtained their mailing address, and mailed them exactly the same questionnaire with exactly the same photo board on it. That is the first way we covered the online and the offline segments of the population. We did this by sending various groups of commercials to various portions of the sample. In this part of our parallel testing we covered a total of 40 different commercials from this year’s Super Bowl.
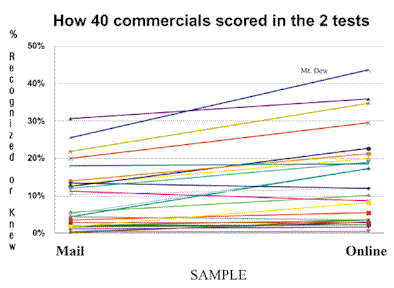
 |
The measure we have on the chart above is one of 50 different measures we take of commercials. We think it is most important for this type of work because it provides a good comparable measure of the number of people that were reached and affected by all kinds of commercials. It shows the number that not only recognized the commercial, showing that they noticed it, it shows if they knew who that commercial was for. A commercial isn’t worth anything if people didn’t notice who it was for. The third element in this three-way measure is likability. The respondent had a favorable reaction to the commercial.
You will recall from the Copy Testing Validity Study completed 10 years ago by the organization hosting this conference, the Advertising Research Foundation, that likability is the best of all the many measures they tested for showing the true effectiveness of advertising. On the left-hand side of the chart are the scores of 40 Super Bowl commercials in our standard recognition-based survey using mail questionnaires. The scores we obtained on the telephone-recruited online survey are on the right-hand side.
As you can see, there is a wide range of scores. These are all commercials that appeared during the Super Bowl so everyone had the same chance to see them; and, the number of people reached and affected varied quite widely. But, the thing to notice in these two types of surveys is their similarity. The commercials at the top of one survey ended up being the commercials at the top of the other survey, the middle ones stayed in the middle and the bottom ones stayed in the bottom…largely the same results from both surveys. We say “largely.” How close was it? We’ll look at the correlation scores to be a little more precise about how close it was. For those 40 commercials in those two tests, the correlation coefficient was a very high .93. That’s an R-squared of .86, which means the online scores reflected 86 percent of the differences found in those base scores: a good, tight correlation.
Do all online methods work?
To find out, we tried two additional methods. One was from the InterSurvey panel. InterSurvey recruits folks from both the online and offline segments of the population by providing WebTV to all of their panelists. That enables all of them to reply to surveys online immediately. We had them send invitations to 1,000 panelists and showed them 13 of the commercials that appeared during the Super Bowl. Those 13 are the base for all of the comparisons we will be making for all four methodologies. InterSurvey received 720 replies, a 72 percent response rate from their panel.
The second additional method used an “opt-in” sample. We were notified about two weeks after the Super Bowl that Survey Sampling finally had the rights to seven million e-mail addresses that could be used for research. They came from a variety of sources, primarily Web sites where respondents left their e-mail addresses along with some information about their interests and permission to contact them about those interests. We sent out invitations to participate in the survey to 4,000 of the folks from that source.
Some would also say this is the cheap-and-dirty type of sample. It was inexpensive. At the time we were setting this up with Survey Sampling they were selling the use of these names for 40 to 60 cents per name. Survey Sampling’s Terry Coen, who is here today, said, “Watch out, our response rates are low. Be sure you send out a lot because preliminary testing showed a response rate of about 8 percent.” I thought, gee we’ve been playing around with a lot of online samples in recent years and have never gotten a response rate that low. Terry was right: we got a response rate of about 6 percent. We see how that panned out on the next chart.
 |
The chart shows the same scores we used on the first chart. We’re not showing indexes or anything other than the actual score these commercials achieved -- the percent that recognized it, knew who it was for and liked it. First from the Internet survey, then from the mail survey, then from the Survey Sampling online sample, finally the Bernett online sample that we already looked at with the original set of 40 commercials. We again see a wide spread of scores from the over 30 percent range down to virtually 0 percent. The top ones stay at top, the middle ones in the middle and the bottom ones stay at the bottom.
We know something about these samples and what makes them different. For the Survey Sampling E-Mail Lite lists, you have to pick the type of respondent you want. We thought people with an interest in football were a natural for a Super Bowl survey. So, what we have in the third column is an online sample of football fans. The Bernett Research phone-recruited sample ended up being the best-educated and the most affluent. That was a normal result of the screening process. When they agreed to participate we asked if they had access to the Internet and if so, would they prefer answering the survey online or would they rather we mail them a questionnaire. Those who took the online option tended to be the computer-literate people who are very comfortable online. All that is reflected in some scores on that chart that might otherwise be thought to be an aberration.
The dark blue line is for the 7Up “Cans” commercial. If you remember it, it involved the phrase “show us your cans” and it showed photographs of people’s hindquarters. Some might say it was a commercial that was not in terribly good taste. Well, the football fans of our population seemed to think it was just fine and tended to like it and pay a lot more attention to it than the better-educated, more upscale folks.
So, we can even explain some of the variations we found between these samples, at least tentatively. Another example where the opposite may have happened is the EDS.com commercial, shown by the light blue line. It’s an electronic data company that would naturally be of greater interest and more likely to capture the attention of the most computer-literate of the bunch, which it did. So, even though these scores are already closely related, there is reason to believe the correlations would be even closer if we could have had exactly the same type of people in each sample.
Again, we made a more quantitative appraisal of just how close they were. For those 13 commercials, when we compare our basic scores from the mail survey approach to the InterSurvey panel results there is an R-squared result of .95. The InterSurvey results account for, or explain or match, 95 percent of the variation in our base measure. For the Survey Sampling sample, even though we got a very light response rate, they ended up producing the same results everybody else did. Specifically, they accounted for 92 percent of the variation in our base sampling. The Bernett Research sample was also quite high. R-squared was .86, slightly lower than the others, but still very high. You don’t get correlations with R-squares that high from data that is not closely related. Our conclusion: all three of those approaches for online interviewing work.
Is there a difference in the cost of doing them three different ways? Yes, that’s shown on the comparative cost chart. We start out with a standard hypothetical telephone tracking survey of 400 interviews; it costs $30,000. It’s the type of survey where half of the cost is fieldwork: for telephone interviewing. The other half is tabulating the results, drawing the charts, analyzing it all and writing the report. That half stays constant throughout all of the examples, only the fieldwork half varies.
 |
When you move to a mail survey of the same length with the same amount of information, the results are delivered to you for $5,000 less: $25,000. We’ve been selling this approach for a long time. We can give you better data based on recognition in a mail survey. We can also make a better argument as the years roll by that our mail surveys are more representative of the total population than telephone surveys. People are busier and using more devices to record and screen calls. Others are using their phone line to connect to the Internet. All of which effectively blocks you from reaching a lot of households.
But we can still reach virtually every household in the country by mail. No matter how busy a person is they are going to come home eventually, and when they do their mail is always there waiting for them. In this type of study we routinely get about a third of the recipients to open our questionnaire, fill it out and send it back -- without any pre-recruiting or follow-up. When was the last time you had a completion rate that high in a phone survey? That’s why we feel our recognition-based tracking surveys conducted by mail on Super Bowl commercials provide an excellent standard for making these comparisons.
We mention this because the people at Harris Black made a good point when they said that the validity of online surveys needs to be checked by anchoring the results to survey results of known validity. They check their online results against the results from their Harris Poll. But that is a phone survey. We would make the point that we are anchoring our tracking results to something even better -- our recognition-based tracking of all Super Bowl commercials by mail that has been the standard in Super Bowl tracking for nine years.
The advantages of mail tracking over phone tracking were impressive enough. But now we can do even better. If you did that tracking survey online using the costs we incurred with the InterSurvey Panel the cost would come down to $21,000. If you used the Survey Sampling opt-in E-mail Lite sample, you could get it done for $20,500, almost the same cost. And, the lowest cost, by a margin that’s not too great, was from the Bernett Phone recruited sample, which comes in at $19,500. Those are substantial savings.
These price comparisons are based on our experience with this set of surveys. I would certainly urge you to talk to the various companies we did business with.
What did we learn from all this?
Insofar as our tests were typical of the broader categories, I think you can say:
- “Opt-in” samples are OK for this kind of work.
- Using phone-recruited samples doesn’t increase costs, it reduces them.
- We only paid a small premium for using a panel, and it does make life a lot simpler to have someone else do all that kind of work.
These conclusions may only apply to recognition-based tracking studies of Super Bowl commercials. Recognition is a very sturdy measure and we’ve proved through the years that it has extremely high test, re-test reliability. And, it also gives you the same results even when you switch methods. We’ve shown that before comparing mall intercept results with mail, with in-office interviewing, with disks-by-mail. And, we are now showing we can get virtually the same results online.
Recognition is not only a sturdy measure, but also reactions to Super Bowl commercials are by design fairly homogeneous. It’s the last of the mass-marketing efforts. Super Bowl commercials are designed to appeal to and capture the attention of everyone: young folks, old folks, rich folks, poor folks. So, we don’t want to over-generalize, but those are the things that we’ve learned from this testing.
What does an advertiser get out of a tracking study?
Paul: Okay, you’ve shown that it produces virtually the same results, better, faster, cheaper. How about a few thoughts on the importance of getting those results? The advertising is over, the money has already been spent. Why does an advertiser want a tracking study like this?
Don: That is the classic question we run into in tracking surveys. Let’s see if we can’t make the point that that is short-sighted.
There are those who say, “I pre-tested those commercials, I’ve done my research. I don’t need anything more.” In pre-testing a commercial, you are attempting to predict how that commercial is going to perform under real-world conditions. When it finally gets on the air, it may or may not perform as your pre-testing has indicated it would. You need tracking research in order to find out. Further, there are three things you have a hard time covering in any kind of forced exposure pre-testing:
- Did it capture attention? Under real-world conditions do they notice it or ignore it?
- How did it do in getting the name of the advertiser across?
- What’s your ROI? What’s the cost per thousand actually reached and affected?
Those are very hard things to simulate in any kind of a pre-testing environment. So, when you’ve done your post-testing, you finally have both creative and managerial feedback on how your advertising performed so you can do more of what works and less of what doesn’t work.
You say you already have a feel for what works and what doesn’t work. You don’t need research to tell you. I think we have some examples from the Super Bowl on what the experts say about that, which may cause you to stop for a minute and wonder if you really do know as much as you think you do. Because if experts are really experts, and expert opinion is all that it’s cracked up to be, everybody should agree. Well, let’s compare the experts’ opinions with our results. It drives home the dangers of relying on expert opinion and the value of a good tracking study.
Rating this year’s Super Bowl commercials
First, we’re going to compare the commercials from this year’s Super Bowl that everyone’s talking about, those dot-com commercials. We do that as a separate group because there is some additional information available about that group. Bob Garfield at Ad Age rates all the commercials. When we looked at the scores for the 15 dot-com commercials the three that he gave the highest ratings to and the three that he gave the lowest ratings to are shown in the first column in the chart below. Let’s compare those with the scores USA Today gave when they did the fabulous job they do every year for the advertising industry. The morning after the Super Bowl they print the scores that they get from having a number of people in different cities watch the game and use little dials to indicate how much they like each commercial while it runs. Their measures produced the set shown in the second column as the best and worst. They are not the same commercials. Already we have some differences.
 |
Next we have a set of scores from Media Metrix. They measured the increase in the number of people using each of these sites after the Super Bowl. How much of a lift did they get in the use of their Web site? Kforce.com was at the top of their list. Schwab was at the bottom. Again, we don’t agree. What is the real picture? Here are our results: FedEx, Pets.com and E*Trade reached and affected the most. Kforce.com, Media Metrix’s best, is our worst. So who’s right?
We differed the most from the Media Metrix rankings, and the reason is understandable. The differences Media Metrix was measuring were increases in hundreds of thousands of hits on Web sites. The differences we were measuring were differences of tens of millions in the number that recognized commercials, knew who they were for, and liked them. We were measuring massive differences in awareness and favorable reactions. They were measuring the tiny fraction that took immediate action. We see no reason to doubt both are valid measures of what they purport to measure.
Next, let’s broaden our view and look at all of the Super Bowl commercials. The next chart shows what Garfield said were the best of all the commercials: E*Trade, FedEx, NFL Properties and the rest. They are compared first with what USA Today said were the best. They are not the same. They have Bud with the crying dog at the top. So what are the best commercials? The last column shows what we found. You’ll see up at the top M&M - the commercial we say is the best of all commercials on this year’s Super Bowl. None of the others had picked it. The reason reveals something important about our methods. We think we are measuring something the others tend to overlook - branding - the commercial’s ability to get across the name of the product. We tend to assume if someone sees a commercial they know who it is for. From decades of testing I can assure you that is not the case. These M&M commercials do a fabulous job of keeping attention focused on the product. You see those little candies in almost every frame and you know what the product is that is being advertised.
 |
A lot of other Super Bowl commercials got down-rated by us because of the number of people who said “Yes I remember that commercial, but darn, I just don’t remember who it was for.” Hardly anybody said that for the M&M spot. That was the edge that put them on the top of these otherwise very excellent commercials. It is something Garfield has to allow for judgmentally. We offer this as hard evidence that he underestimated the importance of good branding. When USA Today has people turning dials to show how much they like commercials, they ignore differences in a commercial’s ability to get the name across. An uproariously funny commercial that never even showed or mentioned the product could get a high rating with their system.
Picking favorite Super Bowl commercials has become almost as much of a national pastime as the game itself. We could go on for hours talking about their real strengths and weaknesses, as revealed by our recognition-based tracking. But, back to our focus of the day: those people who feel they don’t need ad tracking. As soon as they get the commercial produced and on the air their interest drops, they feel their responsibility ends, and their job is over.
If pretesting, your own expert opinions, and the expert opinions of your colleagues were all that was needed to turn out great advertising, you would not find the enormous differences in the performance of Super Bowl commercials that we have seen. And you wouldn’t find the differences we have seen in the after-the-fact judgments on what worked best.
So, we have used these Super Bowl results to drive home a very simple, fundamental point: You need good ad tracking research so you can do more of what is working and less of what isn’t.
The ultimate applications: ROI & marketing models
Paul: You have shown why we need ad tracking. But, how do you actually put that information to work? What are the ultimate applications?
Don: There are two, and they are closely related. First, good, recognition-based ad tracking enables you to measure the cost-effectiveness of your advertising in ROI terms: the cost per thousand actually reached and affected. You can use the same approach that we’ve just been describing for commercials to also get those measures for Web sites, print ads, store displays, and most other elements in your marketing mix. In each case, you show pictures and ask, “Did you see this?” If they did, you ask, “Do you remember who it’s for?” You ask them diagnostic questions to see if they had a favorable reaction to it. At that point we know if each of those efforts is paying its way - whether they are worth doing.
Then you put those results into marketing-mix models to find the most effective combinations, so you can optimize the marketing mix. I had the pleasure of giving a talk last October on marketing-mix models. The main point was that in order to get marketing-mix models to give an adequate reflection of the effectiveness of advertising, we need to build-in the quality of the advertising. Far too many models just throw in the dollars that were spent for advertising, and don’t pay any attention to whether it was good advertising or bad advertising, better than last year, worse than last year. Just dollars, and dollars and dollars. When you spend a million dollars to air Commercial A and it reaches and affects twice as many people as when the same amount is spent to air Commercial B, the “quality” of the first commercial is twice that of the second commercial. You need to factor that quality difference into your marketing-mix models before you can expect them to work, before you can expect them to account for and predict the changes in your market share. In order to know what the quality of the advertising was you need a good tracking study. And finally, I hope we have shown you a good tracking survey is more feasible than ever, because you can get a tracking study that is better, faster and cheaper with this online research breakthrough that we’ve been talking about today.
Notes
1 For documentation of the points made on recall vs. recognition see:
(Studies that show recall is not the best)
Russell I. Haley and Allan L. Baldinger, “The ARF Copy Research Validity Project,” Journal of Advertising Research 31 (March/April 1991).
Leonard M. Lodish, et al, “How TV Advertising Works, A Meta-Analysis of 389 Real World Split Cable TV Advertising Experiments,” Journal of Marketing Research 32, May 1995.
(Studies that show recognition is the best way)
Surendra N. Singh, Michel L. Rothschild, Gilbert A. Churchill, “Recognition vs. Recall as Measures of Television Commercial Forgetting,” Journal of Marketing Research 25, February 1988.
Herbert E. Krugman, “Low Recall, High Recognition of Ads,” Journal of Advertising Research, March 1986.
Wolfgang Schaefer, “Recognition Reconsidered,” Marketing & Research Today (ESOMAR), May 1995.
Hubert A. Zielske, “Does Day-After-Recall Penalize ‘Feeling’ Ads?” Journal of Advertising Research 22, February/March 1982.