Consider the source
Editor’s note: Annie Pettit is chief research officer at Toronto research firm Conversition Strategies.
When was the last time you carefully crafted a survey, designed perfectly-worded questions and then passed the survey out to anyone who wandered by you on the street? When was the last time you spent hours building the most balanced and unambiguous survey and then calculated the results using just the first 1,000 returns, of which 900 were from women and 100 were from men? When was the last time you carried out marketing research with a complete disregard for sampling and weighting?
Clearly, you haven’t. So why do we throw the concept of sampling and weighting out the window when we think about social media research? Sampling is a mainstay of nearly all marketing research because it is neither financially nor logistically feasible to capture the opinions of every single individual in a research population. And, we usually have a goal or strategy in mind, a reason for talking to the people we talk to, when we’re developing a research program.
Social media research embraces the same tenets as other types of research such as survey research. It is not feasible to scour the entire Internet every single day searching for every last mention of every brand. Databases are not large enough to hold all of that data, nor are the days long enough to find all of it. Effective sampling for social media research, therefore, entails gathering sufficient data from sufficient sources such that the sample of results gathered can be generalized to a wider population. A well-developed sampling plan ensures that the full range of online opinions and perspectives is reflected in the data in the appropriate proportions.
Traditionally, sampling is used to identify which groups of people, perhaps business owners or mothers of teenagers, will be asked to respond to a survey. In the social media research space, sampling doesn’t refer to the selection of individuals based on their demographics but rather to the selection of Web sites based on the type or description of the source. As such, the sampling frame for social media research consists of all blog entries, status updates, product evaluations, video and photo comments, forums and many other types of written contributions on the Internet.
An important consideration is that researchers can only sample from publicly available verbatims. Some Web sites, such as Facebook, only release certain pieces of information to the public Internet because the users have given Facebook permission to share it. It is, of course, possible for a researcher to log into their own personal Facebook account and read or harvest the private information, but this is simply not feasible or ethical. Other Web sites, such as Twitter, only publicly release a portion of their data. Even though it is possible for a researcher to sign into Twitter and access all of the data, it may not all released outside of Twitter.
Working hand-in-hand with sampling to promote the reliability and validity of results is the process of weighting. Weighting means that results from certain subgroups of people are given more or less prominence when the results are being calculated. For example, if the intention of survey research is to produce results that generalize to the general population, it is important that the survey sample consists of men and women in census-representative proportions. If sampling is unable to accomplish this, then skillful and appropriate weighting can create the desired effect.
Make the difference
In the case of social media research, the combination of sampling and weighting ensures that even when the quantity of data coming from different sources changes from week to week, the change won’t bias the results. Given the penetration rates and active user rates that vary tremendously by Web site, sampling and weighting can make the difference between valid and invalid results. For example, consider a situation where one particular Web site has many users who make comments, of which only a few are released publicly by the Web site. Then, consider a second Web site that has fewer users who make many comments, of which a larger percentage are released to the public. A research plan needs to consider whether it might make sense to allow one source to overpower the results, or if sampling and weighting must be used to equalize the voices.
Let’s consider a specific situation. Using Alexa (www.alexa.com/siteinfo), we determined the penetration of seven very large, global Web sites. Most people are aware of these Web sites even if they don’t use them. Among Internet users, about 34 percent use YouTube while about 7 percent use Twitter. Then, we gathered a random selection of data from the Internet that mentioned the iPad and reviewed the sources. During the same time period, only 2 percent of our sampled data came from YouTube whereas about 62 percent came from Twitter.
Does this mean that Twitter users are the people appreciating and buying the iPad? No. Does it mean we should allow the 7 percent of people on Twitter to let their voice - which is 62 percent of the data - overwhelm the rest of the data to be the final voice of the iPad? Maybe. Maybe not. Does it matter where the data comes from?
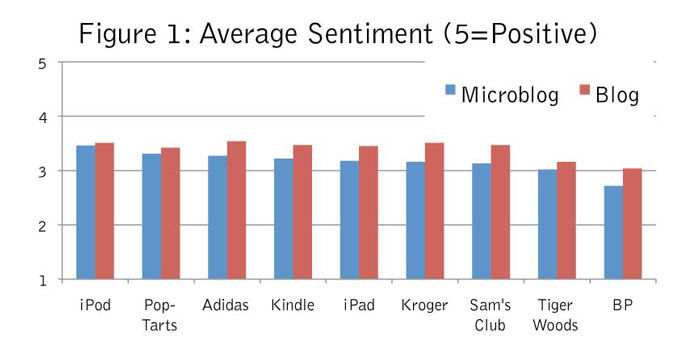
The fundamental reason for sampling is that different people have different opinions. If this wasn’t true, a sample of one would be all you ever needed to generalize to the population. Figure 1 illustrates average sentiment scores for nine different brands. Scores range from 1 (negative) to 5 (positive). Sample sizes for each brand are at least 2,000. The verbatims were grouped according to their source, and in this case, we focused solely on microblogs (such as Twitter or identi.ca) and regular blogs (such as Blogger or WordPress).
Verbatims on microblogs generally have a more negative tone than those on blogs, perhaps because microblogs are more likely to reflect off-the-cuff opinions while blogs are generally more thought-out and rehearsed. And, across the various brands, the difference between the two sources ranges from slight to one-third of a point on a five-point scale, a significant difference for market researchers.
But, average scores aren’t the entire story, as market researchers understand the importance that top-box and bottom-box scores have as estimates of “passion.” In Figure 2 the brands are compared using top two-box scores, or the percentage of verbatims that generated a positive sentiment.

Unlike average scores, top two-box scores fluctuate wildly from source to source. For the Adidas brand, microblogs and blogs produced very similar top two-box scores of around 50 percent. However, for Kroger, microblogs generated top two-box scores of about 68 percent while blogs generated scores of about 40 percent. Blog postings are generally more positive than microblogs, but the trend is very unstable. In the practical world, the effect of gathering data from different sources without considering sampling or weighting means that differences can easily reflect a vendor’s data collection practices as opposed to generalizable consumer opinion.
What follows is a practical example of how the lack, or misuse, of weighting systems can affect research results. Using the same sample of iPad data, which was gathered from a variety of sources such as blogs, microblogs, news sites and comment sites, top two-box scores were calculated in three different ways.
Fluctuating: Top blue line - Scores were averaged together and sources contributed different proportions of data during each time frame.
Stable: Middle red line - Scores were weighted such that each source contributed a similar percentage in each time frame. For example, if blogs contributed on average 25 percent of the data, then verbatims from blogs were weighted to contribute 25 percent of the results in each week.
Microblog: Bottom green line - The weight of microblogs was increased and made stable from week to week.
Though all three methods show increases and decreases in sentiment at similar time frames, the magnitudes of those changes resulted in very different trendlines (Figure 3). Depending on the weighting system selected, completely unwarranted business decisions could easily be made. (Note: The iPad was released on April 3, 2010 in the U.S., and May 28 in Canada and Europe.)
Depends on the purpose
So, what is the right weighting scheme to use? Similar to survey research, there may not always be a perfect weighting system that can account for data collection vendor differences, data cleaning processes and other intricacies of social media data. The choice of a sampling plan depends on the purpose of the research and how those results will be used afterwards. Just as we have learned to create and use the appropriate sampling plans for survey research, the same holds for social media research. But there are some simple starting points from which many more options will evolve.
Option 1: Raw and unweighted
Using data in its raw, unweighted form is most suited for customer relationship management work. The volume contributed by sources will fluctuate from time period to time period, and reflect the priorities of the data collection vendor. However, sampling processes are not required in order to identify individuals who have complaints and then react to those complaints.
Option 2: Stable weighting
This is a simple weighting option that ensures that each source contributes the same volume of data in each time period. Single sources can be weighted up or down as desired, but the system ensures that volume spikes of one source do not affect the entire set of data. This is one method for countering the effects of vendor differences.
Option 3: Internet-representative weighting
Use a third-party source such as Alexa to identify the penetration of various Web sites. Then, apply those penetration rates to the data such that results are weighted according to Internet penetration as opposed to vendor data collection strategies.
Treasure trove
Social media data is a treasure trove of potential insight. We have learned that simply gathering data and averaging whatever numbers result can easily lead to the dissemination of misinformation and ultimately to poor business decisions. Understanding the complexities behind sampling and weighting is one step toward improving the validity and reliability of social media data and social media research.