Editor's note: Steven Gittelman is president of Mktg, Inc., an East Islip, N.Y., research firm. Adam Portner is senior vice president, client development at Research Now, San Francisco.
Social network growth statistics are staggering. What once was a phenomenon popular only with the young now has broad demographic reach. Facebook alone has a half-billion pre-profiled respondents in comparison to seven million panelized double opted-in respondents who constitute the core of online research as we know it today (ARF 2009). This disparity highlights the critical shortage of respondents that exist in our online panels. Thus, where opportunities afford themselves, we must have methods that are tested for their inclusion.
The online panels appropriately seek to avoid overuse of their respondent base. The inclusion of social network respondents should relieve this pressure. In addition it allows the market research industry to involve people in research who might not participate in online panels. The result is a more comprehensive and inclusive sample frame.
In this two-part article (part two will appear in December) we seek to determine the degree to which a social network population sourced from Peanut Labs respondents could be blended with an established panel, Research Now’s American Valued Opinions Panel (VOP) while maintaining the original panel sample characteristics.
The key to quality
There is an old adage in carpentry: measure twice, cut once. What appears as a simple axiom is a robust statement of the entire sphere of quality standards from ISO to Six Sigma. Our carpenter friend holds the key to quality: good measurement tools, precision, fit-for-purpose, metrics and record-keeping. If he is sloppy with the tape measure and cuts prematurely, his craft will suffer, gaps will appear due to his lack of precision, a roof might fail to hold a snow load or, in the case of a cabinet maker, the work will be shoddy and loosen at the seams.
When we blend samples, we must rise to the standards of the fine craftsman. Clearly, the challenge behind combining sample sources is one of proper metrics, precision in measurement, properly-crafted tools and an overriding sense of the purpose for which our samples will be employed.
Minimum measurable difference
In quantitative research we speak in terms of statistically significant difference when comparing populations. There is a threshold at which the difference is so slight that statistics fail to discriminate difference and we presume the two populations to be similar. We coin here the phrase “minimum measurable difference” to refer to the smallest difference between two populations that we can discriminate through statistics.
More normally, we would express populations to be different by establishing an alpha value associated with the precision or likelihood that two samples are different. Thus, we might declare two populations different at an alpha value of ≤0.05. In situations where our measurements are less precise, we might settle for a shaky alpha ≤0.1. Often we make such compromises when compelled to work from samples that are either small or variable.
The minimum measurable difference is a means of determining the threshold at which we begin to detect statistical difference at an alpha value level so low that it represents a conservative measure of similarity. Anything below the minimum would be considered to be an undetectable difference that lends credence to the statement, “As much as we fail to detect difference, we can declare the two populations similar in the metric that we are evaluating.”
Here we choose to set our alpha value levels at one standard error for a sample size of 1,500. Examination of sample sizes among online research studies conducted by Mktg, Inc. showed that less than 5 percent of studies we have performed employ samples of more than 1,500. This is a conservative standard.
We need metrics
Our days are ruled by measurement. Intuitively, we understand metrics to gauge temperature, humidity, pressure, automotive velocity, our blood cholesterol, the calorie content of our food and so on. The science behind measurement is at times so exact that it is no wonder that statistical significance in the hard sciences often begins at an alpha ≤0.01 and beyond.
Establishing metrics that reflect populations and their behaviors is a difficult task. Speak to the next Six Sigma Black Belt with whom you become entangled and you will be given a hard lesson in the need for measurement and associated standards. Difficult or not, we need metrics to establish and maintain quality.
The word “representative” drives fear into the hearts of many members of the market research profession. In fact, we wither at any question of what our sample might represent. Here we reject demography as the only suitable stand-alone standard for online market research samples. When we attempt to calibrate behavior by demography alone, we assume that a proper distribution of demography assures us of a reliable sampling of behavior. We have found that highly-nested demographic samples of different online sources yield significant and meaningful behavioral differences between populations (Gittelman and Trimarchi, 2010).
Our standards have to relate to the measures that we seek to represent. The need for these standards is at the crux of blending online samples. We must blend to a relevant target. In market research we measure behavior. Often the purchasing patterns, buying behavior and other predilections of our target audience are the most germane subjects of our interest. Thus, in creating our metrics, we employ segmentations based on buying behavior, purchasing intent, media preference and sociographic behaviors. The metrics we use at Mktg, Inc. are the result of highly refined segmentations, collected in 35 countries and tested over a four-year span with over 200 online panels.
We seek to determine the degree to which social network respondents emanating from Peanut Labs can be blended with panel respondents who belong to Research Now’s American Valued Opinions Panel. Our analysis included 4,009 U.S. VOP respondents (9/14/2010 – 11/1/2010) and 3,871 U.S. Peanut Labs respondents (9/14/2010 – 12/19/2010), using identically-nested Sex x Age x Income.
The distribution of behavior segments represented by highly balanced samples of VOP acts as our standard. We might use other standards but here we seek to sustain consistency of the VOP sample as we add respondents from Peanut Labs. We use an iterative model to determine how many social network respondents, originating from Peanut Labs, can be added before we detect a minimum measurable difference in the blended combination. Our purpose here is to achieve a consistent blend to eliminate changes in survey data that might otherwise be created by changes in the underlying sample frame.
Likely to be different
Social network respondents are different from those now drawn from double opt-in panelized respondents. These differences are inherent in their reasons for being online. Those who are using the social network arena to communicate with others, obtain news or be entertained are likely to be different from others who are participating only for online purchases, doing their banking or searching for the best deal on an airline ticket. Those who embrace the potential of the Internet for social interaction are systematically different from those who see it merely as a means to expediting their offline lives. As many of our online panels are sourced from a combination of commerce sites such as frequent-flier, various reward programs or simply special interest groups, they are likely to be different from someone seeking social contacts or the latest viral treat on YouTube.
At first, we are challenged to understand the differences and to establish methods for blending this new wave of respondents into existing panels, while maintaining consistent results. Users of these panels must be assured that the addition of any new source, including social networks, will not introduce instability to the samples and increase the variability in their data.
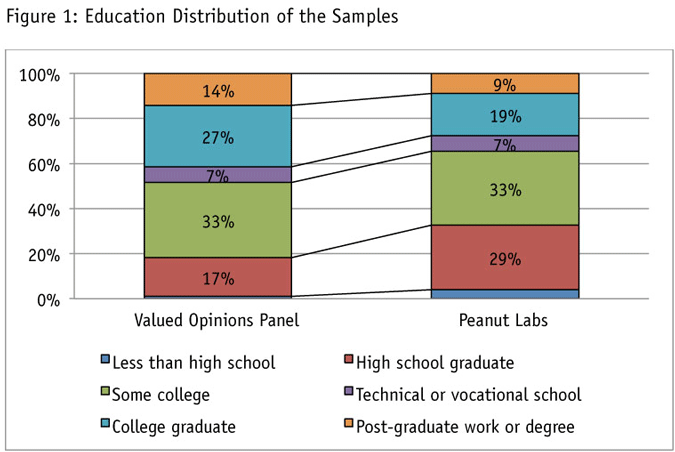
While we attempt to control for differences in our respondents via demographic quotas, it’s clear that individuals from social networks are considerably different. When examining education (Figure 1), among social networked individuals, with identical sex x age x income distributions, we find a far less-educated population than the ones derived from a typical online panel. But while these differences are suggestive of underlying problems, demographics do not tell the whole tale.

Social network respondents are different from panel respondents and the degree of that difference dictates the number of social network respondents that can be added to an existing sample frame without changing the behavior represented by the original panel. The issue is further complicated as we drill into different demographic groups. We find that the differences between groups are not consistent. As a rule, older respondents are more different than are younger ones.
Structural segments
Individual consumers have different motivations and habits, with different factors influencing their adoption or purchase of a particular product or service. With demography insufficient to independently represent each of these consumer segments, it is important to form a typology through which they might be identified to ensure a behaviorally-consistent sampling frame. The process of identifying structural segments can be thought of as having four steps, going from the selection of the variables through identifying segments and developing a regression model: Select Variables + Cluster Analysis + Logit Regression Model + Test Results.
This task is done with a substantial set of data, within a single country in order to provide a stable structure. The parameter estimates from the resulting regression model are then used to assign segments for all other datasets, creating an internally consistent set of distinct respondent groups. The requirements for an acceptable structural segmentation scheme are formidable in that the resulting scheme must consist of highly distinct groups whose differences are reliable across samples. The resulting model must provide clear assignments of respondents to segments, which may require several iterations of this process until the ideal group of variables is identified.
Respondents completed a 17-minute standard questionnaire covering media, technology usage, lifestyle and purchasing intent. These questions were utilized to create a standard battery of three structural segments: 1) buying behavior, describing generalized purchasing behavior and involving 37 questions; 2) sociographic behavior, describing lifestyle choices, with 31 questions; and 3) media usage, describing general modes of media consumption, with 31 questions.
Each respondent was assigned to one segment in each of the three segmentation schemes, with each scheme consisting of three or four segments. For example, the average young male would be classified as a purchaser in the buyer behavior segmentation, as being social networked in the sociographic segmentation and as a regular Internet user in the media segmentation. The composition of each segment is displayed in the following sections.
Buyer behavior segments
The buyer behavior segments capture major differences in respondent purchasing behavior. Figure 2 shows the standardized profile of the segments based on the questions included in the executed questionnaire. These cover both frequency of use and of purchases and attitudes. These profiles show the degree of impact the variables have in determining a respondent's behavioral classification. Deviations from zero indicate the impact on the respective segment in either a positive or negative direction.

Figure 3 shows the distribution of these segments between the host, VOP, and the alternative source, Peanut Labs. Note that these are significantly different overall. Differences, of course, would be expected to vary in subgroups of respondents within these sources.

Sociographic segments
The sociographic segments capture population differences in attitudes, behavior and, to some extent, lifestyle. Figure 4 shows the importance of the various questions used to formulate this segmentation scheme. As in the last section, these are standardized profiles.

Figure 5 shows the distribution of sociographic segments between the host and the alternative source. Once again there are very large differences.

Media usage segments
The media usage segments capture the sources of information and use of media by respondents. As before, Figure 6 shows the relative importance of the various responses from the questionnaire to forming the segments. It should be noted that the segment on Internet usage is expected to be dependent on the sources of respondents.

Figure 7 shows the distribution of media usage segments between the two sources. As would be expected, this indicates major differences.

Sustaining the consistency
Social networks are here to stay and people across all age groups use them to interact every day. Now it’s a matter of incorporating these powerful sources smoothly, at a frequency that expands our sampling reach while sustaining the consistency of our sample frame.
How do we establish the blending percentage that gives us the best of both worlds, increased coverage and reliable data? We are at a new horizon where the blending models we select must be tested with high levels of rigor to assure our clients that the changes in the data they perceive are real and not the product of shifts in the underlying sample frame.
To avoid variability, social media respondents must be blended by design within a panel source. The segmentations herein allow for behavioral standards by which we compare different sample sources. By identifying groups of respondents who answer similarly across a broad array of behavioral items, we divide them into segments. This behavioral fingerprint is an essential measurement tool.
In the December issue, we will cross this new threshold and explain how we bring Research Now’s Valued Opinions Panel and Peanut Labs together without disrupting the flow of data so important to the future of our industry.
References
Gittelman, Steven and Elaine Trimarchi (2010). “Online Research ... And All That Jazz! The Practical Adaptation of Old Tunes to Make New Music.” ESOMAR Online Research 2010.
Walker, Robert, Raymond Pettit and Joel Rubinson (2009). “A Special Report From The Advertising Research Foundation: The Foundations of Quality Initiative - A Five-Part Immersion into the Quality of Online Research.” Journal of Advertising Research 49: 464-485. 2009.