Mixed methods
Editor's note: Nina Rook is principal of Marketing Resources, a Tacoma, Wash., research firm.
Is the Internet just another useful way to collect data, or is it a whole new research paradigm? How does Web-collected data compare with more established data collection methods? Do you have to be a digital wizard to work with the new medium? How effective is the Web when you are surveying IT decision-makers? A project fielded in May of last year gave me an opportunity to explore these questions, and to see what evolving Web technology provides for a researcher looking at complex B2B issues in the IT market.
The project
My client, a developer of Internet management software, needed information to support market development efforts. This included prioritizing product features for the development team, exploring messages, and identifying promising segments. We conducted focus groups to explore issues and language, then developed the survey. It was a long survey - more than 50 questions - generating a complex dataset which could be analyzed using multiple techniques. The study was to be conducted blind. The target respondents were IT decision-makers and influentials who were involved in Internet management and security. We suspected that larger companies - defined as those having more than 500 Internet-connected PCs - might have distinct needs and were especially interested in looking at respondents from such companies.
IT professionals are notoriously hard and expensive to reach by phone, so phone calls were never considered for data collection. For some years, a reliable way to reach them has been disk-by-mail. The classic form is a mailing with good production standards, comprising a customized letter with a $1 incentive, and a prepaid cardboard mailer. Often, the respondents are also offered a summary of the results of the survey. The survey is programmed taking advantage of standard computer-aided interviewing (CAI) techniques. The respondent puts the disk into his PC (most of these respondents are male) at his convenience, fills out the survey, and then mails back the diskette. The data is loaded into a database for analysis.
In my experience, studies using this method have been reliable in the best sense of the word: they have provided information that has turned out to be good. For example, two studies in consecutive years for one client produced sales trends forecasts which were more accurate than those produced by internal forecasting or by the third-party research houses in the industry.
Response rates for disk-by-mail depend on the salience of the topic, the quality of the mail list, and whether the respondent has an ongoing relationship with the identified sponsor of the research. For software customer lists, response rates of 30 percent or more have not been uncommon.
However, times and technology change. Because the study was blind and would use purchased lists, we could not be confident of the historically high response rates. Our study was on Internet management; there is something inelegant about asking an Internet expert to use a disk. Disk-based responses might under-represent the most Web-savvy individuals, who might turn out to be key in our market. Conversely, Internet surveys are an evolving medium: I did not want to rely solely on untried techniques. So we decided to field the two approaches in parallel, sending out a disk-by-mail survey, and posting an equivalent survey on the Web.
The disk side was a well-developed if laborious process: I programmed the survey using familiar PC-based tools, worked with my excellent list broker to find a paid magazine subscription list with the right reputation in the market, which would give me the qualifying sorts that I wanted and that permitted survey use. In-house staff cleaned the list and generated letters and labels; a media house duped the disks and assembled the mailing. Because we were posting the survey on the Web, we included the survey URL in the letter, to allow our respondents a choice of response mechanism and further encourage response. The question was - what was the parallel Web-based process?
Approaches to Web-based surveys
There are as many approaches to surveys on the Web as off the Web. Think of the differences between a hotel leave-behind satisfaction survey, a multi-page "check the box" incidence study for consumer products, and a CAI-implemented, richly textured phone survey. Each has its uses, but they are very different. Web surveys also come in many forms. They can be presented as short pop-ups on specific gateways or Web sites, as panel studies, or through e-mail solicitation. One vendor even offers to intercept traffic to specific sites, so that you could potentially survey your competitors' customers.
The most difficult problem for us was that we needed highly qualified respondents. We settled on the Web-based equivalent of the disk-by-mail method: sending e-mails to lists of (hopefully) qualified respondents, with the URL of the survey embedded in the e-mail, and the offer of an incentive (in this case, the same summary of results offered to the disk recipients, and a chance to win a $500 shopping spree).
Fielding the survey is two sets of tasks: programming and hosting the survey, and recruiting respondents. Because I anticipated that finding good ways to recruit respondents would be time-consuming and difficult, I decided to concentrate on that phase and not to host the survey myself. I found a service provider, NetReflector.com, whose business model seemed to fit my needs. The process went smoothly. Programming the survey one more time was tedious, but necessary to running parallel forms. It was also slow, even with a DSL line, compared to PC-based programming. While I did not take advantage of all the analytical capabilities that NetReflector provided, I found one aspect very useful. They provided the researcher - and anyone else she shares the appropriate URL with - with real-time "marginal" analysis. In this project, this offered reassurance that things were working, that respondents were interpreting questions right, while the continuous count allowed me to tailor the right level of e-mail "bursts."
Finding good lists was more problematic. I had a couple of leads from books and articles, and some suggestions from my client's direct marketing arm. My trusted list broker deals with many e-mail campaigns, but could not help me. So back to the Web. I considered panels, but the vendors I spoke with could not provide the right qualifying sorts.
After an extensive review process, I chose two list sources. One, 101Communications, provides e-mail addresses from their print magazine subscriber lists. This was a clear parallel to the disk-by-mail case - while there was a limited number of sort criteria, most people had provided enough information about themselves that the criteria could be used. The service they offered was straightforward. Once I specified the list, they would send me an e-mail pretest of my offer copy, and then mail in bulk. All responses would go directly to the client site, without being routed through their URL. Because of this, no historic response rate data was available.
The second source, Postmaster Direct, had a very different service. They broker lists from many different sources, including many Internet-generated lists, and claim that the names on their list are "double opt-in" - i.e., people have confirmed their willingness to accept e-mails on specific subjects. Their system allows you to build any list you want, using key word searches online to identify a "list" (often one cut of a larger list, defined by product interest, for example). For each list, you can dig down one or two layers to find demographics and average historic response rates. If there are multiple lists that meet the criteria, it is even possible to prioritize by response rates. Once you build to composite list, the system eliminates duplicates and the e-mails are sent. If you choose to route responses through them (i.e., put a URL assigned by them on top of the survey URL) they can provide real-time click-through data on your mailing (for example, how many and what proportion of the e-mail recipients hit the survey URL).
While the disk-by-mail survey was executed as a single shot, the possibility of continuously monitoring marginals, and the relatively short turnaround on e-mail bursts made it possible to fine-tune the number of e-mails sent.
Not quite nirvana
All this is not quite the digital nirvana that it seems. In Web-generated lists, only a few people had submitted all the demographic data that was requested. You may know that 70 percent of the list is IT professionals, but you are powerless to exclude the 30 percent who are not. While product interest sorts were available, company size was not. Also, click-throughs are just that - many people click to the survey, take one look, and click right on back.
While the Web sites of the companies I dealt with were bulging with information, the process actually reinforced the value and efficiency of one-on-one conversation with a knowledgeable human. A five-minute conversation which deals with issues at the right level can substitute for an hour of mining a Web site. And people develop expertise: while the composite list I built by rigorous extractions from 80 different sources drew well, its results were matched by a list that had not turned up in my search, that my sales rep recommended in-person.
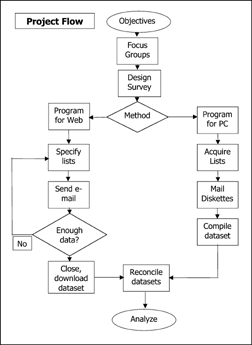
The project flow is shown in Figure 1, while the lists that were used are shown in Table 1.
 |
 |
Response rates
Over 10 percent of the disk recipients responded. This compared to 15 percent to 20 percent for blind surveys two years ago, but with different lists and topics. Thirty percent of these respondents preferred to answer on the Web, which required them to key in a 36-letter URL. The comparable rate two years ago was about 3 percent. Damaged disks, unqualified respondents, and blanks reduced the effective response rate to 8.5 percent. Responses to the e-mails peaked about a day after their being sent, and had dried up within five days. For the e-mail lists, click-through rates ranged from 1.8 percent to 4.6 percent, but there was a fall-off between this and actually providing data in the survey, giving an effective response rate of 1.7 percent (Table 2).
 |
Even when people started the survey, they dropped out before completion. Subscription lists and disks were best, followed by subscription lists on the Web, then Web lists, on the Web (Table 3). The inability to screen for large companies showed up in the responses. The Web-based lists had just 13 percent of respondents from large companies (Table 4).
 |
 |
Subject line key to e-mail response
On an e-mail, the only thing that the respondent may see is a subject line. Of two different subject lines sent over the same split list, one had a 38 percent higher response than the other. This is shown in Table 2.
Once our drop-dead date was reached, NetReflector downloaded the data to me in Excel format, and I loaded it into the disk-based database. This required some non-intuitive manipulations - what one tool coded as "1" (leaving everything else as missing data), the other one coded a "Yes" (coding non-selection as "No"). I suspect that we might have seen wide variations with different incentives, but we were unable to conduct a test in this area.
Does source affect response? At one level, yes; but it was a second-order effect. There were about 70 variables in my results where it was possible to make a simple t-test comparison. Comparing all e-mail to all disk, there were multiple differences, but if I controlled for size of organization - our most important demographic distinction - most of these disappeared, leaving only three relatively unimportant differences. In general, respondents from larger organizations responded in very similar ways, whether they had received the disk or the e-mail. However, there were minor differences when we looked at specific industries - for example, government respondents receiving diskettes were more likely to respond by disk, while computer software respondents receiving the same mailing often answered by the Web.
Cost
Getting data from IT people is expensive, no matter how you do it. It was hard to do a rigorous head-to-head comparison because the fixed and variable cost structures are different for each case and because some of the disk respondents had used the Web. However, in the interests of providing some concrete guidance, I performed a post-hoc cost analysis.
Looking at the overall responses, Web-based responses were less expensive than disk-based responses, even when I included the hosting costs (Table 5). However, when just the prized large company respondents were included, these differences disappeared.
 |
There did not seem to be any clear relationship between list cost and response rate for the Web-generated lists.
Reliability of results
With response rates as low as these, there is a real concern about non-response errors, but there is the same concern with phone surveys with low response rates. Using dual sources provided some assurance that findings were robust.
Old vs. new business paradigms
It seemed to me as I roamed the Web, seeking out suppliers and optimizing the design of this study, that there are three groups of service providers on the Web. One group comprises companies that have grown up with direct marketing or research, and put an e-business front end on their established services. They have long seen themselves as one part of a complex solution, and their Web business replicates their established service online. While these organizations may understand research, they do not offer increased value in the new technology.
A second group is technology-savvy and extends a lot of benefits of Internet technology into this environment, giving researchers unprecedented feedback and control of the process. Some of these organizations tend towards a "be your own researcher" message, which underplays the difficulty of framing research questions, study design, and especially conducting thorough analysis - all of which are key for the robust findings that people need for good decision-making.
Third, there are, of course, companies that offer soup-to-nuts research focused on the Internet as the data collection medium - at the risk of allowing the data collection mechanism to drive the research design.
The data collection mechanism is just one of the many design decisions required in good research, and the Web is just one more data collection mechanism, however smart. My experience with this study has shown that the services are now in place so that a researcher who is prepared to think things through for the needs of a specific project can take advantage of Web technology if and when it is appropriate.