Editor’s note: Donald E. Bruzzone is president of Bruzzone Research Company, Alameda, Calif. This article is adapted from a presentation at the IIR Conference on Marketing Mix Modeling in Chicago on March 21, 2002.
The object of marketing mix modeling is to learn the most effective ways to increase sales. To do that you need valid measures of every element in the mix - everything that could be affecting sales. This article focuses on measuring the true effect of one of those elements, advertising. It concentrates on advertising because a major reason many marketing mix models don’t work as well as they could is that advertising is only represented by dollars or GRPs.
Let me set the stage with examples I’ve used before. In the simplest of situations where just two factors are expected to account for all the changes in a brand’s sales, the problem model looks like this:
(A x Advertising GRPs ) + (B x Price) = Sales
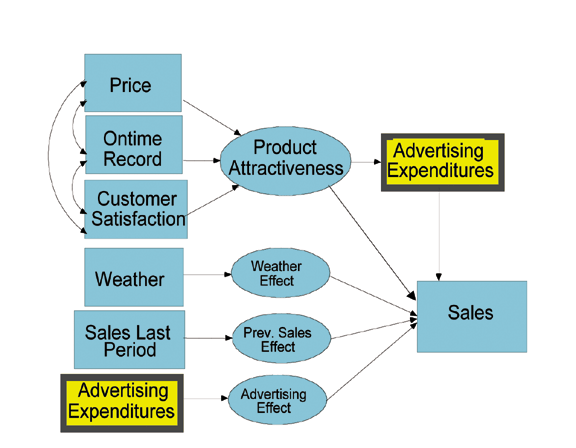
Many variations of this basic problem will be encountered in marketing mix modeling, including models that are more sophisticated and complex (Figure 1). The problem with these models is they assume all advertising has the same effect. That is the same as saying bad advertising contributes as much to sales as good advertising. This article stresses the importance of making that portion of a marketing mix model as realistic as possible, and reviews the best ways of doing it.
 |
The measurement problem
Businesspeople have developed an admirable ability to represent complex relationships mathematically. For many elements in the marketing mix this ability is decades ahead of our ability to measure those elements. That’s why I feel an up-to-date review of the ways to measure advertising should be very productive. A case can be made that inadequate measures of advertising’s impact has caused serious harm in our economy.
There is one prominent exception to that generalization about having inadequate measures of the various elements in the mix. It’s price. Scanners have given us near-perfect information in that area. We found clear relationships between price and sales. We didn’t find clear relationships between sales and other elements in the marketing mix - like advertising. Lots of package goods brand managers concluded: “Price affects sales, advertising doesn’t.” And they acted on that. Their view of marketing mix models: “It is a black box into which you shovel numbers, turn the crank, and out comes what the boss thinks is the optimal marketing budget.” That uncritical, unthinking use of any tool spells danger.
The damage that was done
Modelers at the time should have kept reminding those who were using their models of the correct conclusion: “The figures we put in the model to represent the effect of advertising didn’t help account for changes in sales.”
There should have been warnings because what happened next, after scanner data became available, was a major change in virtually the whole package goods industry.
Price promotions increased, advertising decreased, and packaged goods switched from being one of the most profitable segments of the economy to one of the least profitable. Therefore, the issue of how best to measure advertising is not a trivial refinement. A good case can be made that faulty measures of advertising’s true effect, used in marketing mix models, have ruined profits in a whole sector of our economy.
What was wrong with the advertising measures?
Measures that only showed the volume of advertising were used for years during this period in marketing mix models. Usually it was total dollar expenditures or gross rating points. The latter, usually referred to as GRPs, measures the volume of advertising by adding up the rating points of each program the commercial appeared on. Rating points, in turn, show the percent that was watching the program. These are figures the firm already has for other purposes, so they have always been readily available to modelers. But their use in models ignores the problem cited earlier: The assumption that bad advertising does as much to increase sales as good advertising.
Almost everybody involved in advertising has experienced the thrill of a winner and the agony of a bummer. They know there is a big difference. But there appears to be a mindset among modelers, and the management that is responsible for them, that finds it easy to accept a different view. They see the key question as “What is going to happen if we do a little advertising, a lot of advertising, or no advertising?” This willingness to accept the premise that all advertising is going to have about the same impact needs to be challenged. It needs to be challenged because it is now evident that a big part of the problem was that most modelers and their management did not take the rather obvious limitations of advertising volume measures seriously. There wasn’t the impetus to do what is necessary, and spend what is necessary, to get more valid measures of advertising’s effect on sales. It shows an urgent need to look at the evidence showing the quality of advertising is at least as important as the volume of advertising.
The amount of difference between good, average and bad advertising
Some of the most clear-cut and conclusive evidence on this point is provided by Super Bowl commercials. It comes from our firm’s database built from tracking the impact of every Super Bowl commercial aired during the past 11 years.
 |
We check a cross-section of the public a few weeks after every Super Bowl. We wait a couple of weeks to see how many of the Super Bowl commercials had any lasting effect on people. We start by finding out how many still recognize the commercials. That shows the attention-getting value and the memorability of the commercial. We also see if they remember who it was for. That shows how well it was branded and how well it performed in getting across the most important piece of information every ad has to communicate. Those two measures only show if the respondents noticed the commercial. They don’t show if it had any effect on them. To measure that, we ask how well they liked it, the measure the famous Advertising Research Foundation Validity Study indicated was the one most closely related to sales. If they pass all three tests we consider them reached and affected.
Some Super Bowl commercials are aired only during the game, and never again until our interviewing is complete. Those are the ones plotted on the chart in Figure 2 - and they are the ones that prove the point.
- Exposure was identical — and under real-world conditions.
- We found the results were not identical.
- The difference was the quality of the advertising.
The long yellow bars on the chart show the percent that recognized these 99 commercials ranged from over 50 percent to less than 5 percent, an impressively wide range for commercials that all had an identical amount of exposure.
The red bars show their branding ability also varied widely. For some commercials almost everyone who recognized the commercial knew who it was for. For others, hardly anyone did.
The blue bars show the percent that passed the first two tests, and also passed a third test: they liked the commercial. This measure revealed even more variation between the commercials.
The amount of difference that can be found between the top commercial and the bottom commercial in a comparison like this can be dismissed as a rare and unusual difference. None of the others differed by as large an amount. So to provide evidence on the amount of difference that can normally be expected between “good” and “bad” advertising, we averaged the performance scores from the top 20 percent and the bottom 20 percent.
 |
An appendix at the end of this article contains all of the data from the 99 commercials plotted on the chart in Figure 2. It details the commercials that were in each group, and shows how the averages for the top 20 percent and the bottom 20 percent were calculated. The table in Figure 3 compares those averages, and shows there was a wide difference between the performance of the “good” and the “bad “ commercials.
Among these 99 commercials that all had an equal amount of exposure under normal, real-world conditions, the top 20 percent were recognized by four times as many as those in the bottom 20 percent. They were four times as likely to be noticed and remembered. When we move down a line and consider the number that both recognized the commercial and knew who it was for there was an even bigger difference. And when we move to the last line, using all three measures, we get the biggest and most important difference. The “good” advertising reached and affected eight times as many as the “bad” advertising.
When you consider this comparison is based on Super Bowl commercials, it could be understating the true difference. Advertisers were paying millions for this single airing, so they were doing everything they could, using the best and brightest in the business and giving them big production budgets, to insure they had a good commercial to run on the Super Bowl. Because of this, you would hope the number of bad, ineffective commercials on the Super Bowl would be somewhat less than you usually find on TV.
At this point some might be wondering, “What’s the big deal? Who argues with good being better than bad?” That is critical. All who are using just dollars or GRPs in their marketing mix model are arguing with that. They are arguing that having good advertising is no better than having bad advertising.
Consider the magnitude of the difference. Advertisers in the top 20 percent got eight times as much for their money. That’s big. Who even fantasizes about an eightfold increase in their ad budget next year? You can’t expect a model to fit without allowing for this.
How could it fit when some ad dollars are eight times as effective?
Confirming evidence from other sources
Have other researchers found the same thing? That’s always a wise question to ask. In this case confirming evidence is available from many other sources. Probably the largest, most carefully conducted and most persuasive is the study popularly known as Adworks One. It was headed by Len Lodish of Wharton and supervised by research directors of 40 major advertisers. (Lodish, et al, “How TV Advertising Works: A Meta-analysis of 389 Real World Split Cable TV Advertising Experiments,” Journal of Marketing Research, May 1995.)
The participating companies pooled their results from this most expensive and conclusive procedure for measuring the effect of advertising on sales to see what could be learned. Two key findings were relevant to the issue of whether creative quality is more important than volume.
- When the testing procedure was used to see if new commercials produced greater sales than old commercials, that type of change was often accompanied by sales increases. The new commercial could have been better, or the old commercial could have worn out. Both reflect the current quality of a commercial.
- When the same test was used to see if increased GRPs or expenditures produced greater sales, that type of change was seldom accompanied by sales increases.
Changing the commercials changed sales. Changing volume didn’t. This classic study showed quality was not just as important as volume, it was more important.
Speakers at conferences on advertising research have provided another type of evidence. Our firm keeps track of them by publishing our Top Ten Insights, a short two-page recap of conferences that we have been sending to customers and colleagues since 1995. We have just reviewed all of them to document two key points:
- Many conference speakers have said quality is more important than volume.
- No conference speakers have said volume is more important than quality.
There is more, but that should be enough to document a point that few researchers outside of modeling would argue with. It is hoped at least this much can be of help, because most of the current marketing mix models our firm is aware of are still using just GRPs or dollars to represent advertising. They are still assuming volume accounts for everything. And that bad advertising accounts for just as much as good advertising.
In case the problem is not knowing how to fix the situation, we’ll move on to a review of the solutions. One of the things we hear from modelers is that they don’t feel comfortable being put in the position of an expert in advertising research. They don’t like having to pick one measure of advertising’s impact over another.
The question we hear most frequently about marketing mix models from non-modelers is the simple, straightforward question of “Do those things really work?” That’s fairly simple to answer. Put historic information about price, advertising, and all the other elements in the model. Did it “predict” what actually happened to sales? If not, you have clear evidence your model doesn’t work. If it does, you at least have reason to believe it may prove as successful in predicting the future as it did in accounting for the past. If it accounted for some, but not all, of the past changes, you have reason to keep working on the model to see if you can find what is missing. The following review of opportunities for measuring advertising’s true effect should help both groups.
Measuring the quality of advertising
There are many ways to measure the quality of advertising. Most will usually help improve model fit - at least a little. The best will almost always help - and they will help a lot. The moral we would offer: Try to get the best, but don’t ignore any.
- Subjective measures: What you hear about the advertising from friends, at home, in the office are all examples of the type of thing that should not be ignored. If nothing better is available, think about the general thrust of the comments you are hearing. Are they primarily positive or negative? With a conscious effort to be objective, this information can often be used as the basis for classifying current advertising as above average, average, or below average. When a simple three-level classification like that is factored into a marketing mix model it is often enough to produce a measurable improvement in the model’s ability to account for past changes in sales.
Focus groups can be used the same way, as can critics’ reviews, and any awards the advertising might win. Anything that can be used to help decide if the advertising is above average, average or below average is worth trying to see if it improves the fit. Modelers who say they have to stick with volume-based measures of advertising because they cannot afford anything better are not really trying.
- Pretesting gets into more quantitative measurement of ad quality. Often modelers feel bewildered by the many different types of pretesting they are faced with. Their firm uses many and they don’t know which to place the most faith in. The chart in Figure 4 may help. It categorizes all pretesting in terms of where it falls based on two characteristics: how the advertising is shown to the respondents, and what is measured by the questions the respondents are asked.
 |
It shows the least valuable pretesting uses forced exposure and cognitive measures. (“Look at this commercial. What is the main point it is trying to get across?”) Even though that has been a popular way of pretesting for decades it suffers from two near-fatal flaws. First, it forces people to look at the advertising. The greatest danger any advertising ever faces is being ignored. It follows that an ad’s ability to capture attention is an essential attribute. When you force a person to look at advertising you don’t learn anything about that. Second, it concentrates on message comprehension. Understanding the message isn’t nearly as important as understanding the effect that message might or might not have on a person. The Advertising Research Foundation Validity Study showed main point recall was not closely related to sales. Those who remember the message might not find it believable, or important, or persuasive. The ARF Study showed the effect on their attitudes is what is important. That’s why likability turned out to be the most predictive of all measures. It was actually more predictive than direct questions about future intentions to purchase, or simulated purchasing decisions before and after exposure. However, those behavioral measures did have substantial predictive value, so we have shown both behavioral and attitudinal measures on the right side where you find the higher value pretesting.
The second requirement for the best pretesting is to make respondent exposure to the material as normal as possible. This is done best in the split cable testing cited previously. Respondents are not aware they are seeing different commercials in the normal course of watching TV at home than people in another matched panel that might be watching the same program. But the cost of split cable pretesting is well up in the six-figure range and it takes six months to a year, so faster, less expensive methods of simulating normal exposure are more popular. The most common is to embed the commercials to be tested in new program material that is shown to respondents who might think they are going to be questioned about the new program. This gives a more normal opportunity to either notice or ignore the advertising.
It is important to note that all pretesting is an attempt to predict how advertising will perform when it actually runs under real-world conditions. The scores that advertising achieves in pretests are valid only insofar as they help predict its actual performance.
It is easier and more accurate to measure the impact of advertising after it actually ran. So, tracking (or “post testing”) provides the best data for modeling. Its general superiority is also emphasized in one of the best and latest books on measuring the impact of advertising. The author, Robert Heath, concluded: “Pretesting is always an option, but tracking is usually mandatory.” (Robert Heath [2001], The Hidden Power of Advertising, WARC, Henley-on-Thames, GB.)
Tracking
This type of testing, done after the advertising has run, is typically conducted in one of two ways.
- Recall-based telephone tracking surveys: Here the key question is usually of the form “Do you recall seeing or hearing any advertising for Brand X recently?”
- Recognition-based tracking conducted online or in malls: In this approach the material is shown to respondents and they are asked if they remember seeing it. Since it requires showing things, it cannot be conducted over the telephone.
It raises one of the oldest issues in advertising research: Which is the best measure of advertising’s success in getting noticed rather than ignored: recall or recognition? This gets into our firm’s specialty, ad tracking. We feel the difference can be summarized quite succinctly: When people say they recall recent Brand X advertising they could be thinking of last year’s advertising, or even the competitors’ advertising. But when you show it to them and ask, “Do you remember seeing THIS commercial?” you get a massive increase in accuracy.
To determine if advertising has any effect on people, you need to do the most accurate job possible segregating them into two groups: those who noticed the advertising, and those who either ignored it, or never had an opportunity to see it. Only then can you demonstrate with confidence that people reached by the advertising bought things, did things or believed things that the rest didn’t.
I feel the reason recall has failed to show any significant relationship to sales in industry-wide studies of ad testing validity during recent decades1 is a direct result of its lack of accuracy. Recognition capitalizes on one of the great strengths of the human mind. People can recognize things they have seen before easily and with great accuracy. Usually a little introspection on past difficulties recalling names or phone numbers is sufficient to demonstrate that is not the case with recall. The mind’s ability to recall things from memory is definitely not one of its strengths.
In short, when the question is what is the best way to measure advertising quality, the answer is recognition-based tracking.
How many ways are there to reflect the effect of advertising in marketing mix models? Which are working best?
- Measures of advertising volume: Their limitations have been covered previously (Don Schultz, professor emeritus at Northwestern, has aptly characterized them as “media tonnage models”). But even though we deride them, many continue to use them exclusively, and I think the rest of us will agree they are vital elements that need to be included in more complete and complex models. That leaves the question of what is the best measure of the amount of advertising: dollars or GRPs?
The answer is the same as it is for many ideas about model improvement: Try it, and see if it improves the model’s fit. (Did the “predicted” sales, or market share, for past years come closer to what actually happened?) This is most often measured by r2, that ubiquitous measure used in many fields to show how close you came to accounting for what really happened. I have never found a statistics text that gave a clear-cut, unqualified statement as to what is acceptable in r2 scores, so I offer the following as my personal and somewhat subjective calibration of r square scores for marketing mix models.
The meaning of r2 scores for marketing mix models:
100%: You cheated!
98%: Your seat in the researcher’s hall of fame is assured.
90%: You definitely deserve that raise, and a promotion.
70-80%: You have a good workable model that should help the firm improve its batting average in making marketing decisions. Just don’t bet the whole farm on it.
50%: Don’t waste my time by asking me to look at it.
Returning to the question of whether there are meaningful differences in the various measures of advertising volume, the answer is yes. One hundred household GRPs means the number of homes that had their TV on and tuned to the right channel while your commercial was playing was the same as the total number of households in the area. This does not mean the commercial played in all homes. It may have appeared several times in some and never in others. The point is, the number of times the commercial appeared in homes is a fixed number. A given number of GRPs means your commercials appear a given number of times. Yet, when you buy that number of homes during the prime evening hours you pay about three times as much as if you bought the same number of homes (same GRPs) during daytime hours. Some GRPs cost more than others because those who buy and sell GRPs agree some are worth more than others. Those who have their TV on during the day are likely to be doing something else at the same time. During the evening they are more likely to be devoting their exclusive attention to the TV.
This is background for a key possibility: Since you tend to get what you pay for, dollar expenditures may be more closely related to advertising impact than GRPs, or TRPs (TRPs are the closely related measure of how often the commercial could be seen by those in the target group the advertiser was particularly interested in reaching). The way to find out is to put the other measure in the model and see if it fits better. We know of a number of cases where this improved the fit. There was also one case where expenditures had been used initially and switching to GRPs improved the fit. It is a switch that is easy enough to make, so testing it both ways is recommended.
- Allowing for diminishing returns: When successful advertising stops - advertising that has resulted in a measurable increase in awareness, sales, etc. - the awareness, sales and the rest won’t immediately drop back to their original level. Typically they drop back gradually over a period of days or weeks. The time it takes to drop halfway back is referred to as the advertising’s half-life. This is not allowed for in the simple “media tonnage model.” But it can be allowed for by building in fairly simple sub-models of advertising’s half-life called ad stock models. If advertising starts running again before the ad stock value has dropped back all the way to its pre-advertising level, it will tend to rebound from that new level and reach levels higher than before. When these models can be fitted to a substantial amount of historic weekly data, it will show what the product’s half-life is and how much advertising needs to be conducted and at what intervals to keep the results from falling below some predetermined level.
The second type of diminishing return comes into play when the opposite condition prevails. When expenditures or GRPs are kept at the same level for a period of time, the measurable impact of that advertising will eventually start to decline. It wears out and won’t produce as much impact as when it first appeared.
It is becoming clear both types of diminishing return should be expected and allowed for in building models. But it is also becoming clear there are no standard decay rates that will fit all products and all types of advertising. It takes a substantial amount of historical data to find the values in the model that will provide the best fit.
Models that use nothing but GRPs or dollars will miss the effect of both types of diminishing return. Building an allowance for them into the model is one of the first things to try to see if you can’t get a better fit. There is another way around these two complications. They are both short-term effects. If the main use of your model is to optimize the annual marketing budget, don’t go through the agony of fitting your model to weekly data. If you can use annual data, both of these thorny problems should disappear.
To incorporate ad quality, a multiplier function is best
Ad quality is easy to quantify. Say you have spent $10 million airing Campaign A. Your tracking survey shows it reached and affected 10 percent of the population. Then you spent the same amount, $10 million, airing Campaign B. Your tracking survey shows it reached and affected twice as many: 20 percent of the population. Campaign B was twice as cost-effective. That difference in quality is best reflected with a minor addition to existing marketing mix models that only use advertising expenditures. You take the $10 million expenditure for Campaign B and multiply it by two.
That simple change should improve the fit of the model. Previously, it only included the $10 million expenditure for each campaign. That told the model they were equal. They weren’t. When you multiplied the $10 million for Campaign B by two that told the model it was twice as effective as Campaign A. It was. That made the model reflect the true conditions in the market more closely, so it fit better and achieved a higher r2.
All advertising expenditures could be adjusted in the same way. If an adequate tracking survey had been in place, the adjustments could cover all media, all markets and all years. In each case the expenditures would be multiplied by the same type of quality factor: a factor that shows how efficiently that advertising reached and affected people in that year, in that market. Quality could be expressed in relative terms. That’s the way it was done in the first example. Campaign B was twice as efficient as Campaign A. Quality could also be expressed in terms of a fixed scale. It could be the ratio of the advertising’s quality to the average for that product, the average for all advertisers in the category, or the average for all advertising - period. The model structure could be exactly the same as for the “media tonnage” model. The only difference would be that every time an advertising expenditure figure or a GRP figure appeared, it would be multiplied by a factor representing the advertising’s quality. This is a procedure foreseen and allowed for by leading modeling theorists2.
Another approach: dummy variables
If the marketing mix model is being fitted to a very large, continuous database it is possible to “deduce” the quality of advertising by inserting dummy variables in the model. There is a dummy variable for each commercial or ad. It is given a value of 1 during weeks when it is running and a value of 0 when it isn’t. When regressions or other procedures are run to see how well the data performs in predicting sales or market share, the coefficient that is put in front of the dummy variable shows how much of the change in sales or market share - change that was not accounted for by any of the other variables - was accounted for by the appearance of that ad or commercial. This indication of the ad’s effectiveness could be affected by both the quality of the advertising and the amount of advertising. Hopefully, advertising that had a large amount of exposure during a week when the dummy variable was given a value of 1 would have a greater effect than advertising that was given little exposure. So, as long as the volume of exposure that ad or commercial was given is shown by a separate variable, the value of the dummy variable coefficient should measure the quality of advertising.
The big advantage of the dummy variable approach is that tracking surveys to measure the quality of the advertising directly are not needed. On the other hand, the dummy variable approach can be characterized as “backing into” ad quality, since it shows the change in sales that couldn’t be accounted for by anything else. It is subject to the classic limitations of dummy variables. If anything else tends to happen at the same time as the advertising (the product goes on sale, salesmen make more calls, etc.) the dummy variable will not provide a clean reading of quality. Further, they are subject to all the noise, and overemphasis on chance occurrences that happen to make the data fit better, common to most multivariate procedures. Still, where tracking surveys are not available, but lots of other data is, the dummy variable approach should provide a better fit than when ad quality is ignored completely.
Elasticity - be alert to its effects
However, watch out what you say about elasticity. In our experience it is the most misunderstood element in the advertising section of a marketing mix model. You hear things like, “We don’t advertise, because for us, it’s inelastic” from half-knowledgeable MBA-types. Beware of those kinds of misinformed pronouncements. Some understanding of advertising elasticity is essential. It is the main reason for picking one type of model over another. To review the basics:
 |
Some examples with simple numbers should help isolate the source of the confusion. First, an example where the increase in sales is greater than the increase in advertising: it yields an advertising elasticity greater than 1, meeting the requirement for being considered “elastic.”
 |
But note the second example: a $2 million increase in advertising produced a $5 million increase in sales. It is correctly shown as inelastic, but it is a profitable application of advertising. Those half-knowledgeable MBA- types were thinking of price elasticity, where inelastic is always bad. If your increase in sales is less than your decrease in price you are bound to lose money.
My advice: avoid ever using the phrase “advertising elasticity.” Put everything on an ROI basis. Talk about a positive or a negative return on the investment in advertising. That second example may have been inelastic, but it showed a positive return on the additional investment in advertising.
However, you cannot ignore elasticity completely because the main criteria for deciding whether one form of model fits your needs better than another is usually how they handle elasticity. Here’s a recap of what happens with the most common models3:
- Linear model: elasticity never drops below 1 as share approaches 100 percent.
- Multiplicative model: elasticity stays same as share approaches 100 percent.
- Exponential model: elasticity stays same as share approaches 100 percent AND elasticity grows infinitely as mix elements grow infinitely.
- MCI model: elasticity declines to zero as mix elements approach infinity.
- MNL model: elasticity grows then declines as mix elements increase.
There is a moral to this: Check your model to be sure you have a good fit and one that keeps producing reasonable results when you approach extreme values outside the range covered by your historic data base. If your historic data doesn’t vary much you may find all models fit because things have not been changing enough to show if any of the models fail to fit at more extreme values.
Currently, many people in marketing have occasion to use marketing mix models that they didn’t develop, and where they don’t have an intimate understanding of the inner workings of the model. To protect themselves on the advertising front I would urge them to spend a few minutes entering hypothetical numbers for advertising volume and noting the results.
The numbers they enter should range from zero to hundreds of times greater than the highest conceivable ad budget. If it shows you could capture 110 percent of the market, or if it shows the last million dollars you add to the ad budget yields a billion-dollar increase in sales, you should question the validity of the model. It appears to have one of the elasticity problems shown for the first three models.
The last two models are generally preferred because they never produce impossible elasticities for advertising or any other marketing input. What they produce is shown in the charts in Figure 5 and 6. Compare the charts with the results you achieved testing your model and you will learn a lot about your model.
 |
 |
As the volume of advertising increases does advertising elasticity increase until it reaches some maximum and then starts declining until it reaches zero, the way it does in the first chart? Then it is likely to be an MNL (multinomial logit) model. This is the model that sources like the Cooper, Nakanishi text, cited earlier, recommend for advertising because it reflects a threshold effect where small amounts of advertising have little or no effect. As advertising volume increases, each additional dollar of advertising has greater and greater impact until it reaches the optimal point. Then diminishing returns set in and the curve turns down, eventually returning to zero. That pattern fit the consensus opinion at the time about how advertising worked4.
Now, thanks to the more detailed data on sales and exposure to advertising that has become available from single-source research, and John Philip Jones’ work with that data5, it appears the consensus has shifted to one supporting the picture shown in Figure 6.
John Philip Jones was the first to capture the industry’s attention with new single-source evidence showing advertising has its greatest impact when it first appears, not after it has been shown several times. His findings have been supported by other prominent media researchers such as Erwin Ephron, who uses them as the basis of his recency theory, which favors continuous, rather than pulsed, advertising6, and Collin McDonald, whose early work with single-source data 35 years ago provided much of the data cited in support of a threshold effect, but who has now come around to the view that although threshold effects exist, they are neither common nor normal7. There is also a growing realization that one curve does not fit all products. USC’s Gerard Tellis summarized it this way: A threshold effect is most likely to be found when the brand is unfamiliar, the message is complex, or when it is new or novel. This suggests another reason support for threshold effects may be declining: Are more of today’s ads just simple reminders for well-known brands?
Even though the consensus may be that the MCI (multiplicative competitive interaction) model should provide the best fit for most current advertising, that is an assumption that needs to be tested whenever enough data is available. With enough testing, modelers may be the ones who make it possible to plot advertising/sales curves with more confidence in the future.
Use share models
The final issue in successfully modeling the true effect of advertising is to allow for what the competition is doing. Models that only account for what a single firm is doing may work, but only until there is a major change among competitors. Every firm is affected by what its competition does, so models that allow for that are the only models that should work. The arithmetic gets more complex, but fortunately the principles are the same, formulas are available in any good modeling text, and today’s computers have little trouble handling the complexities. Advertising is expressed in a “share of voice” form:
 |
Note that quality is included as a multiplier, just as it was in simpler versions of the model. The other elements in the marketing mix are expressed in essentially the same manner. Price is usually expressed as a ratio of the firm’s average price to the average price in the industry. The model is set up to predict the firm’s share of industry sales rather than the firm’s dollar sales.
We find some have difficulty in seeing any logic in the assumption that a competition’s advertising can change the effectiveness of the firm’s advertising. They readily accept the principle that when a competitor cuts their price the firm is going to lose sales. The same principle applies to advertising. There are only a fixed number of consumers who are susceptible to switching brands or increasing consumption. When a competitor captures a portion of them with their advertising, there are fewer left to capture with your advertising. In short, your advertising will produce more sales when your competitor has a poor campaign. When the competitor has a dynamite campaign that same advertising will produce less sales.
Even though share models are more likely to account for what is going on in a market, they do have one limitation: They require more data. In most product categories there are services or trade organizations that provide the necessary information about sales, prices, the amount of advertising for competitors and/or the industry as a whole. Getting a measure of the quality of their advertising is often an unmet need. However, it is a need that can be met by tracking the impact of all the advertising currently being conducted in the category. A tracking survey like the recognition-based tracking survey conducted each year to track the impact of each of the 50 or 60 commercials on that year’s Super Bowl can provide precise measures of the quality of every ad and commercial running in almost any category.
The challenge is in the future, not in accounting for the past
Modelers’ obsession with historic data can cause some in management to lose sight of what a marketing mix model can accomplish. It can tell you if doubling the sales force or investing the same amount in price promotions is more likely to increase next year’s profits. It’s designed to show the best ways to increase future profits. The modeler’s fixation on accounting for what happened in the past is just one critical step in building a valid tool for predicting the future.
Similarly, some ask, “Why spend the time and effort measuring the quality of past advertising? You don’t know what the quality of future advertising is going to be.” There are three answers to that. First, if the firm’s advertising, or its competitors’ advertising, was unusual this year — either unusually successful or unusually unsuccessful — the model shows what to expect next year when conditions are likely to be more normal. It avoids the trap of projections inadvertently based on the assumption that unusual conditions are likely to persist, when they are not likely to persist.
Second, it can be used in setting goals for pretesting next year’s advertising. If the new advertising tests out at certain levels, it is likely to have the quality specified in the model in order to achieve the expected market share. A coordinated program of pretesting and then tracking the advertising’s actual impact after it runs can be used to calibrate pretest results so they will provide valid estimates for the quality multipliers to be used in the model.
The third is related to the second, and may be the most important of all. When the model is used to show how much was added to the bottom line by good advertising, and how little was added by bad advertising, you have what is needed for a key ROI calculation. How much can you afford to invest in additional research and additional ad development costs if it holds promise of producing better advertising? If your experience is like that of the Super Bowl advertisers cited previously it could mean getting a $10 million dollar ad budget to yield the impact of an $80 million budget. The chance of getting an increase like that could justify a substantial investment. The investment would be likely to have a return many times greater than an investment of the same size in a greater volume of advertising.
In short, when ad quality is included in marketing mix models, marketing management gets much closer to its preeminent goal — the information that allows them to do an effective job managing the firm’s marketing.
References
1 For example, see “Effectiveness Coefficients” in Lee G. Cooper and Masao Nakanishi, Market Share Analysis, Kluwer Academic Publishers, 1988.
2 For a detailed description of these models and the elasticities they produce, see Lee G. Cooper and Masao Nakanishi (1988), Market-Share Analysis, Kluwer Academic Publishers, Boston Dordrecht London, International Series in Quantitative Marketing.
3 Michael J. Naples, “Effective Frequency: The Relationship Between Frequency and Advertising Effectiveness,” Association of National Advertisers, 1979.
4 John Philip Jones, When Ads Work: New Proof that Advertising Triggers Sales, New York: Simon & Schuster-Lexington Books, 1995.
5 Erwin Ephron, “Recency Planning,” Journal of Advertising Research, 37, 4 (July/August 1997).
6 Collin McDonald, “From ‘Frequency’ to ‘Continuity’ — Is it a New Dawn?” Journal of Advertising Research, 37, 4 (July/August 1997).
7 Gerard J. Tellis, “Effective Frequency: One Exposure or Three Factors,” Journal of Advertising Research, 37, 4 (July August 1997).
 |