Sampling the impact
Editor’s note: Don Bruzzone is president of Bruzzone Research Co., Alameda, Calif.
A number of survey-taking behaviors have been found to negatively impact data quality. After isolating eight of them, we conducted a research-on-research study to answer a specific question: Did these eight factors affect the actual answers we were getting from standard ad-tracking questions?
We measured each of them in a large-scale national online survey of broad interest: our firm’s 17th annual Super Bowl Study, which tracked the impact of all 55 of the 2008 Super Bowl commercials. Thanks to the active collaboration of Survey Sampling International (SSI), Shelton, Conn., in five days starting a week after the game ended, we received 5,155 replies from both existing and newly-recruited panelists.
In summary, we found that three had a noticeable effect: completing the questionnaire unusually fast; straightlining answers; failing to follow instructions (such as: Check “b” below). The remaining five factors had little or no consistent effect on the answers: how frequently they took online surveys (including never before); how many panels they belonged to; were answers to conflicting questions consistent?; did zip code and state match?; did they say they might buy a non-existent brand?
The proportions of the sample shown to have quality problems by these measures were usually small. We only removed 2 percent. And as shown later, the effect they did have was not very dramatic. The difference they caused in performance scores didn’t approach the differences we find between good and bad ads.
Straightlining is a special case. If these results can teach us anything about questionnaire construction, it is to avoid listing a lot of alternatives with a grid full of check boxes for the answers. People find that boring. Many will straightline at least some of them and that can have a measurable effect on their other answers. (It suggests using things like Flash-based card sorting instead.)
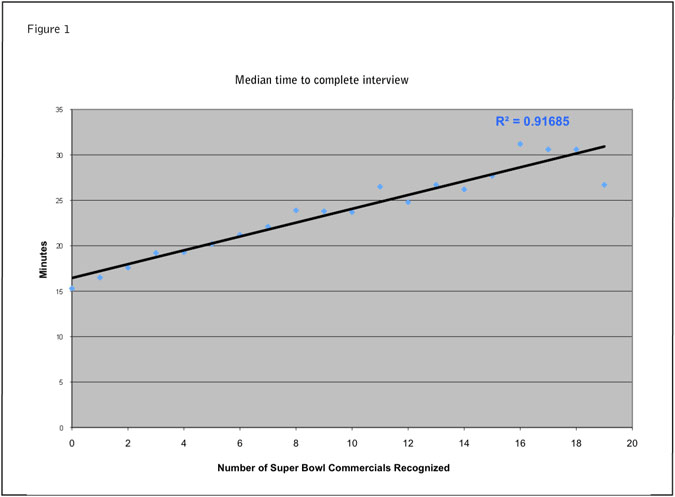
Figure 1 shows the base for our measure of how fast the respondent completed the questionnaire. The median time had a high correlation (r2 = .92) with the number of commercials the respondent recognized. That is because whenever they recognized a commercial they were asked additional questions about that commercial. That median time became their “norm.” The tabs in Figure 5 show 3 percent finished their questionnaire in less than 50 percent of the time that was their norm. That 3 percent was the group that showed the most dramatic differences in ad performance scores.
There were some interesting directional differences. It is probably no surprise that these speeders said they recognized fewer commercials. But the interesting part is that they were more likely to come up with the correct name of the advertiser for the commercials they did recognize. This suggests speeders don’t stop and agonize over commercials they were not sure of. They were about half as likely to check “Not sure, I may have” when answering our recognition questions. So it appears they tend to say they recognize commercials only when they are positive they have seen them before, and this is what leads to a higher percent getting the name of the advertiser correct.
Figure 1 is included because it is the basis for a somewhat different approach to identifying speeders. The approach used in a frequently-cited ESOMAR paper “The Effects of Panel Recruitment and Management on Research Results - A Study Across 19 Online Panels” (Vonk, van Ossenbruggen and Willems, 2006) was to look at completion time without any adjustments. However, the authors noted that some respondents had a tendency to show less familiarity with ads to avoid follow-up questions. In their study, faster speeds caused respondents to be classified as “inattentive.” They cited no evidence to back up the claim that the desire to avoid follow-up questions was actually the reason for people saying they were not familiar with ads. So we felt there was a chance they could be classifying respondents as inattentive just because they were honestly not familiar with the ads. Our new measure is designed to avoid that possibility.
Biggest differences
Figures 2, 3 and 4 use a tree-branching CHAID approach to show which of the eight factors accounted for the biggest differences in several measures of advertising impact. It is a process that tried all eight factors not only to make the initial split, but to keep splitting and re-splitting all of the resulting subgroups.


All of the charts show that this new “time index” was one of the top three factors accounting for differences in respondent answers. They also show that, after the samples have been segmented by these three factors (time index, straightlining and following instructions), CHAID proceeded to find additional splits that were statistically significant. We were blessed with enormous samples, so that is not surprising (5,155 respondents each reporting on 18 or 19 commercials gives the base you will see in Figure 2 of 94,698 cases). Although the additional splits may have been significant they were not very meaningful. They were often inconsistent in direction and magnitude. The top three appeared to account for virtually all of the meaningful differences.
Figures 5 and 6 show details on the amount of difference in six different ad performance scores, found at various levels of the eight quality measures. It shows the greatest differences in the first four recognition-based measures were on the first line of differences: the line showing the results for the 3 percent that finished the survey in less than half the normal time. This spreadsheet that shows the effect of each of the quality factors independent of the effect of the others also shows the largest and most consistent differences were related to time, straightlining and following instructions. The remaining factors again tended to show smaller and less consistent differences.

The appropriate test for determining which of these differences are statistically significant, and which are not, is open to discussion in cases like this. After reviewing the options, we colored the cells where the ad performance scores differed by more than +/- three percentage points from the score for respondents in the category showing the fewest signs of suspicious behavior.
Suspicious quality
Figure 5 also shows the percent of the sample showing any of the signs of suspicious quality that resulted in differences in results was not particularly large. More specifically:
Finished in less than half the normal time: 3 percent
Straightlined 60 percent or more of the grids: 3 percent
Didn’t follow an instruction to check “Disagree Slightly”: 10 percent
Fifteen percent did at least one of these three things, but only 2 percent did two or more. This shows these measures did not function as traps that caught substantial numbers of respondents who were giving consistent and repeated signs of answering fraudulently. Most did only one of them. Since a respondent could do any of these inadvertently and without evil intent, we only removed the 2 percent who did two or more in our final tabulations of Super Bowl results.
Four categories
SSI coded all of its panelists into one of four categories to reflect their level of participation in past SSI surveys. It was done for a Washington Mutual study that showed those who take more surveys were less likely to show interest in new products. However, the study also showed they did not answer questions about product use or financial attitudes differently (“Sample Factors That Influence Data Quality,” Gailey, Advertising Research Foundation, September 2008). Since our study had shown heavy responders did not answer differently, we were interested in exploring any differences between our self-reported approach and SSI’s actual panel records. With the approval of Washington Mutual, SSI provided the same information for its panelists replying to our survey. The first thing we found was a lack of correlation between the two measures (self-reported vs. SSI records: r = .004). This wasn’t too surprising. As shown in Figure 6, two-thirds of our respondents were members of more than one panel and this new data only showed what they did with one of those panels (SSI). Finally, the last category on Figure 6 shows the results. Our six measures of ad performance did not show any differences that were larger or more consistent based on these actual panel records than they did for the other five factors on Figure 6 that showed little or no consistent effect.
This was a Bruzzone Research/SSI project, but since both firms are represented on the Advertising Research Foundation’s Online Research Quality Council we took advantage of that group’s knowledge and expertise and asked them to review the questionnaire and the results it produced. We want to express our gratitude for the advice and counsel offered by members of that group.