A review of CBC from Sawtooth Software and Ntelogit from Intelligent Marketing Systems
Editor's note: Steven Struhl is vice president and senior methodologist in the Chicago office of Total Research Inc.
Consumers' responses to products and services can be analyzed in a variety of sophisticated ways using a relatively new technique called discrete choice modeling. Two recently released programs, CBC (Choice-Based Conjoint) from Sawtooth Software and Ntelogit from Intelligent Marketing Systems, make it more feasible than ever to perform your own DCM analyses on an IBM-compatible PC. These programs provide real advances in the automation of many of the more difficult aspects of DCM analyses. Each has strengths and some areas that could use fine tuning. Each also has its own personality, and likely will appeal to a different type of user.
A few other programs that have been available for years allow more analytically advanced users (or perhaps more audacious ones) to do many of the tasks required to analyze a discrete choice problem. The two most fully developed programs are the stand-alone LOGIT module from Systat and the logistic regression module in SAS. The logistic regression module in SPSS also has some capabilities for analyzing this type of problem. These alternatives, however, are generalized logistic regression programs and do not provide features explicitly designed to ease DCM analyses. If you can use any of these products to fully analyze discrete choice problems, you probably should be writing this review instead of reading it.
Ntelogit from Intelligent Marketing Systems
Most striking about Ntelogit is its analytical power. The program was specifically designed to handle large DCM problems, and you can test up to 200 alternatives (products/services) with it. It does not force unrealistic limits on the number of attributes or levels you can test. It is flexible in terms of both the analyses you can perform and the kinds of experiments you can run. And it provides a wealth of diagnostic information useful for formulating sound models.
But the program requires extensive data setup, to the extent that you must manually create product "scenarios" (or "cards"). While Ntelogit runs from a clear, straightforward menu-based system, its use requires some expertise in analysis. The manual provides plenty of excellent pointers on analyzing and interpreting discrete choice models, but the average reader will need to wade patiently through some fairly technical discussions to reach the more useful material.
The program has one particularly bothersome feature. It requires that you use a hardware lock, a small device that fits on the computer's parallel printer port. The program refuses to run without the lock. The lock is designed to protect the work of industrious, impoverished programmers, who otherwise would slowly starve as pirated copies of their program went into nearly universal use. At least, that's how certain software manufacturers explain it.
These locks are a nuisance, though. If you install the program on your lap-top computer and forget to bring the lock, you're out of business. If you put the program on a desktop unit, you have to squeeze behind the PC and insert the device between the printer cable and the computer. If many software manufacturers used these locks, you would need to put your computer six feet from the wall. The lock will work properly only if some other lock does not interfere with it. The locks are vulnerable to static electricity, which causes them to malfunction, and may interfere with utility programs that speed printing. Besides, the numerous companies that do not use locks, Microsoft for example, do not seem to be starving.
Choice-Based Conjoint from Sawtooth Software
This is the most approachable commercial software for DCM. Users who are familiar with any of Sawtooth's other products (Sawtooth's ACA conjoint program in particular) will feel at home with CBC. While it is easy to operate, it has its limitations. Perhaps most restrictive is that each choice (or alternative) tested can have no more than six attributes (although the program does allow each attribute to have up to nine different levels). Also, you cannot simultaneously test more than nine alternatives.
The program has some ingenious features. It generates scenarios for the user that are not necessarily based on standard experimental designs. Rather, CBC can employ random designs, which allow the user to model many types of interactions among product attributes without creating a special experimental design in advance.
Random designs involve mixing up various attribute levels in a random fashion. For this approach to work well, each respondent should get a different set of randomly mixed attributes, and the sample should be large. If too few respondents are used in a study based on a random design, then too many combinations of attributes may never appear together. This can cause problems in trying to estimate interactions or develop even relatively straightforward models.
Since each respondent should get a different set of randomly mixed features in the scenarios he or she sees, this approach also requires PC-based interviewing to work efficiently.
The program runs simulations more easily than does Ntelogit, which requires that you enter either zero values for all choices or create dummy (fictional) data for the scenarios you want to simulate. CBC makes simulation quick and easy by asking only for simple changes in the attribute levels you want to test.
CBC has one other limitation. While it tests designs for correlations, it does not have any direct means of testing for the so-called independence of irrelevant alternative that could cause DCM estimates to be inaccurate. Not testing for the IIA in a DCM analysis is something like running a linear regression with no way to test whether regression errors are related to estimates. While IIA is not usually a problem in practice, CBC would be a stronger product if it allowed users to explicitly test for it.
Finally, CBC takes a somewhat roundabout approach to handling conditional variables (attributes that appear in connection with some alternative or alternatives and not with others). You must use a special "prohibitions file." While this is not hard to do, it is not as direct as simply identifying which variables go with which alternatives being tested.
While both CBC and Ntelogit will do the job, their output is very plain, something like a printout from an old line printer. Neither provides charts or graphs, nor do they work well with the proportional fonts available on most printers. They are limited to basic typewriter-style (nonproportional) text.
How the program works
We tried the two products with test data. Since Ntelogit can accept aggregate-level data, we used it with data from a modified real-world survey. The study includes a story that might enliven this review somewhat - assuming such a thing is possible.
In the study, the client company, Quiet Financial Services (motto, "You Never Heard of Us"), has decided to test responses to their Big Debit card among 150 members of a specific consumer segment. An earlier conjoint analysis revealed that this segment cared most about the interest rate charged for the proposed debit card. The segment was also by far the most profitable, since people who care about the interest rate for a credit or debit card usually maintain account balances and pay plenty of interest charges.
Incidentally, a debit card is like a credit card, but it taps directly into whatever small savings you might have. You pay no interest as long as you do not overdraw your account.
Quiet Financial Services has some details about a proposed debit card from American Express (the project code name for this card, Amex Cash Lamprey). With not atypical modesty, Amex plans to introduce this card with a high interest rate and a fee.
QFS also fears that Citibank will offer a competitive card (project code name, Citibank Invader). QFS has some market intelligence that this move is part of a suspected Citibank plan to take over the visible universe by the year 2006. QFS does not know details of the card, but fears it could be offered at a very low interest rate, with a high credit limit.
The attributes and alternative levels that QFS has decided to test for each card are:
QFS Big Debit
Interest: 11%, 13%, 15%
Annual fee: none, free with checking
Credit limits: $4,000; $10,000
Amex Cash Lamprey
Interest: 14%, 18%
Annual fee: $25, free with checking
Credit limit: $8,000; $10,000; $15,000
Citibank Invader
Interest: 10%, 13%, 15%
Annual fee: always none
Credit limit: 2,000; $12,000
Because the Citibank annual fee is "always none," this attribute will appear on the scenarios, but will not be part of the design.
The analysis using Ntelogit
The attributes and levels to be tested were put into a conjoint-type fractional factorial design. Ntelogit does not require this type of design to run, but since the fractional factorial-type design is both efficient and simple to generate, we used it. Ntelogit cannot, in fact, produce such designs for the user. Instead, you must use another program that does, such as Conjoint Designer from Bretton-Clark software, the conjoint program included in the SPSS Categories option, or ConSurv from the makers of Ntelogit, Intelligent Marketing Systems.
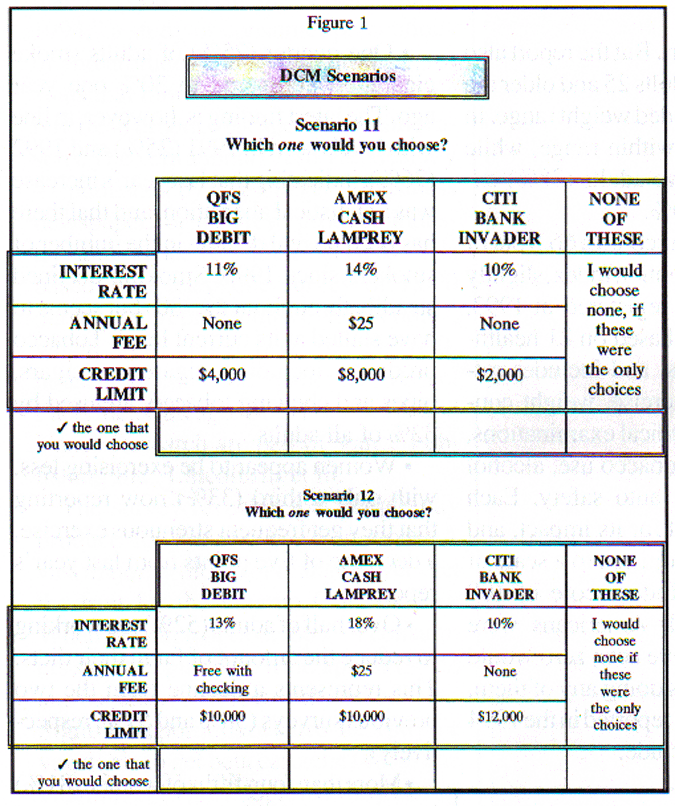
To model this competitive situation, 16 "cards" were generated, each showing a specific combination of attribute levels for each provider's debit card. These cards then had to be rearranged into scenarios. With Ntelogit, the contents of these cards also are needed to generate the DCM command file. Two sample scenarios appear in Figure 1:
The Ntelogit data file
With Ntelogit, you must construct a DCM data file that contains several key elements. You have to construct the file because Ntelogit will not allow you simply to collect the data, fitting responses into a data file that it has built for you. You must set up everything, knowing where all the pieces go. These are the principal components you must specify:
- A variable identifying the alternatives. (In this example, the code for the QFS Big Debit Card is 1; for the Amex Cash Lamprey, 2; and for the Citicorp Invader, 3.)
- A variable showing which alternative was chosen, or one giving a count of how many chose each.
- The design variables associated with that alternative.
- A variable identifying the scenario in which an alternative appears.
Since we also like to include a choice of "none of these" among the scenarios, the minimum setup for four choices (including "none") in 16 scenarios is 64 lines of data. Analysis on an individual-by-individual level therefore would require 64 lines of data per respondent.
Figure 2 corresponds to a few lines from an Ntelogit DCM data file, with added variable labels. The data shown corresponds to the two scenarios in Figure 1. Ntelogit's actual data file would not include the boxes - which have been added here for the sake of clarity - nor would the variable names appear in the file. You would simply type the data in columns in ASCII format and specify the variable names using Ntelogit's menu system.
A few points are worth noting about the data. The "count" column refers to the number of respondents selecting each alternative. Choice 1 is the QFS card, choice 2 is Amex, choice 3 is Citibank, and choice 4 is none. Also, this file shows data at the aggregate level only. Of course, you also can aggregate the data for various subgroups, not just the total sample.
Note also that all variables are conditional. That is, each variable exists only for one of the alternatives. Those variables that require "dummy coding" use a 1/-1 scheme, rather than the usual 1/0 scheme (which uses a 1 when the attribute level is present and a 0 when it is not). Here, -1 means "absent," while 1 means "present."
In the coding scheme here, zero values are reserved for the variables that do not exist for an alternative. The "none of these" alternative (choice 4 in the table) is always represented by a string of zeros.
Dummy codes can coexist nicely with actual values for continuous variables in the data file, as they do here. You probably will get better results by standardizing all the variables (converting them to a common scale with a mean of zero and a standard deviation of 1) when scaled variables and dummy codes are mixed like this.
Key NTELOGIT output
Model Coefficients and Significance Values
We first ran a model with all the attributes present in it. These first figures reflect that model:

Note that only four variables are significant. This information appears in the column labeled"Pr(>|t|)," which indicates the probability values.
There is a problem with this chart. The sign on "qfsint" (QFS interest) points the wrong way - the worth of an interest rate should go down as the interest rate increases. We used Ntelogit to try to rectify the problem, as Ntelogit allows great flexibility in reshaping the model.
Using Ntelogit's simple menu-based system, we tried several steps that we thought would improve the model. We dropped all nonsignificant variables. This didn't help. We exported the ASCII data file to a spreadsheet, added squared, cubed and square root terms for the offending variable, and reimported the data in ASCII form. The new variables didn't help.
Finally, we began dropping the significant variables that seemed less important. Doing this revealed that no model with more than two significant variables behaved sensibly. The sole surviving variables were QFS interest and Citibank interest.
We hope you haven't been holding your breath for this, but the story does have a clear resolution: The two remaining variables are the only ones that truly matter to this segment. Amex interest is too high to matter. Everything else is window dressing.
Let's look at the coefficients for the two remaining attributes:

There is some good news here, but not much: Both attributes are highly significant; QFS interest is more important to customers than Citibank interest. This is shown by the relative sizes of the parameter estimates.
We also encounter some bad news: Nothing about the Amex Cash Lamprey appears to enter into the choice process significantly.
Ntelogit also produces an iteration report, which can be useful in diagnosing the goodness of the model. This report shows how many runs (or iterations) it takes to achieve convergence - or what it takes for the model to settle into a stable pattern.
Most well-behaved models will converge in eight iterations or less. A model that requires 15 or more iterations probably has data problems. It could have, for example, errors in model specification (wrongly identified variables, data in the wrong locations). Other possible causes of nonconvergence include having very infrequently chosen alternatives in the model, or having variables that occur very infrequently.
An iteration report from Ntelogit:

The report shows that the model converged on the second step, so at least it behaved well in this regard.
Ntelogit also provides one of the more common means of diagnosing the goodness of the model, namely the Rho Squared (RhoSq) measure, which is similar to the R2 in linear regression. Like the R2, it varies from 0 to 1.
Incidentally, the RhoSq for the final model was 0.21 (a poor value). However, the earlier model that made no sense had a value of 0.40. Having more parameters in the model usually tends to boost the test values, even if these parameters do not work sensibly together.
The number of respondents that chose each alternative was, nonetheless, reasonably close in each case to the prediction for the final model. This emerged in the prediction report produced by Ntelogit:

Ntelogit also produces prediction success tables and classification tables. These are similar to the correct classification tables produced by discriminant analysis. The classification table is considered a more extreme test, but sometimes the results it produces are slightly better. Ntelogit shows only the observed frequencies (counts), and not percentages in the table body. The last line in the table shows the percentages correctly classified (or predicted) overall.
The prediction success for our example follows. These results are scarcely better than chance.

In the classification table that follows, we see that levels of correct prediction are better for the QFS card and for Citibank, but abysmal for Amex and for those who wouldn't choose any of the three.

Interpreting the output
Knowing interest rates for the QFS card and the Citibank card, we can correctly predict that the QFS card will be chosen about two-thirds of the time. We can correctly predict that the Citibank card will be chosen about one-third of the time. Unfortunately, we have no idea why anybody would choose the Amex Cash Lamprey, or none of the three.
CBC
CBC operates differently than Ntelogit, and consequently, it takes less space to describe its analysis of the DCM problem. CBC is a complete survey system in which you do all of the operations needed to develop the necessary experimental design; you generate the survey instruments and get them out into the field; and you ultimately collect, aggregate and analyze the data. Also, CBC does not provide quite the level of analytical detail that Ntelogit does. It does not, for instance, produce the prediction report or correct classification tables. The main menu from CBC (Figure 4) offers some sense of the scope of its activities.
CBC is strictly a PC-based system. You create and send disks out to the various field locations, respondents use them on PCs, and then you aggregate the data collected. As Figure 5 shows, you must edit several files to get the questionnaire ready to run. These operations are fairly straightforward. The prohibitions file is used to create the conditional variables -- those that appear only in combination with certain choices in the scenarios.

We used the sample data file provided by CBC. The example was a relatively simple one that involved choosing among four notebook PCs. We updated the example to make the PCs more similar to today's choices, and substituted a few foolish company names for Sawtooth's more benign "Brand A" through "Brand D."
Perhaps the most time-consuming (but not difficult) thing about using this program is getting the computer screens, the ones that respondents will see, to your liking. The program requires you to specify coordinates for any boxes you want to appear on the screen, and to follow a fairly strict text format when specifying what goes where. Sawtooth characteristically values ease of use, so we hope they will be moving to a format that employs a more intuitive screen-painting process (one in which you can draw what you would like to see), or perhaps even to a Windows interface.
Figure 6 shows a screen shot of a CBC scenario. Note that all the alternatives being tested do not need to appear in each scenario with CBC. (The screen shot shows only three brands of 
PCs, not all four tested.) This is somewhat surprising. Although this will simplify each task the respondent does, it seems contrary to the spirit of DCM, in which respondents ideally should see a "marketplace" consisting of all alternatives. The set of choices arguably should remain constant for the sake of realism, unless you have reason to believe some products will move into or out of the marketplace, or that product availability could be a problem.
What CBC will produce
Once you have gathered all of the information, CBC continues with procedures to aggregate and analyze the data. The scope of its activities is shown in CBC's data analysis menus:
Let's take a look at the analysis and output possible with CBC. Like Ntelogit, CBC will provide an iteration report and details on the worth and significance of each level of each attribute. This is the output from the "Run Logit Analysis" choice. (The option labeled "Analyze by Counting Choices" also produces a wealth of intuitively approachable output.)

The CBC manual provides some guidance in interpreting the output. Suffice it to say that the model based on the small sample data file (like the Ntelogit example) did not do too well. Most levels of most attributes would not influence the decision. The table provided by CBC would be stronger if it provided significance levels like those in the Ntelogit report.
CBC shows strength in its simulations. You simply type in the attribute levels you would like to appear, and run the simulation. CBC even allows you to interpolate between attribute levels that have numerical values (such as prices).
The CBC simulation reports, like the report from the analysis menu, are quite basic, but they get the job done.
Where else can DCM go?
Dissatisfaction with the alternatives available for DCM analysis several years ago led some companies to write their own DCM software. My experience with a custom package that captured many elements on the DCM "wish list" has led to a perhaps biased view of what DCM analyses can and should do.
For instance, neither of these packages can create a series of "base case" scenarios, consisting of the alternatives in specific configurations, and then show the market share effects of varying attributes from that base case. Is a feature like that necessary to run DCM? Of course not, but once you have access to it, you may find it so useful that it becomes difficult to forego.
CBC has made an interesting advance in its capabilities for generating and using random, as well as standard (fixed), designs. This is a very ingenious approach to the design limitations that DCM sometimes suffers. But random designs are relatively new, and their properties are less well known than standard experimental designs. In particular, sample size requirements necessary for such designs to work properly are not that clear. CBC provides a brief appendix talking about the issue of sample size. But it seems that much more guidance on acceptable minimum sample sizes is needed for the effective use of these designs by CBC users. I hope Sawtooth will provide that guidance in upcoming releases of CBC.
The output of both programs is quite plain. It is restricted to simple, character-based ASCII files. Neither Ntelogit nor CBC puts data into spreadsheet form, nor do they create charts or graphs. DCM analysis leads to a wealth of information that can and should be displayed graphically. These programs' output is far less sophisticated than that of some conjoint analysis programs. In particular, they lag behind the conjoint module of SPSS for Windows, which produces near publication-quality charts of the attributes' importance and attribute-level utilities. As DCM gets more established and as migration from the old character-based DOS interface to Windows continues, polished presentation likely will become the norm. Both programs have their work cut out for them in this area.
Conclusions
Each of these programs will bring you closer than you've ever been before to complete, in-depth DCM analysis. Ntelogit does all that you are likely ever to want in terms of investigating a model. It has complete diagnostics, including largely automated testing for IIA. The depth of its analytical capabilities is excellent. You will probably not encounter any real-world problem that is too big for Ntelogit to handle. You can look at up to 200 alternatives and use huge designs.
But Ntelogit makes you do some of the hard work yourself. It does not, for instance, create the scenarios that you will need to administer the DCM task - you must create these by hand, and you have to have some understanding of how to get a design into scenario form.
Ntelogit is most seriously limited in its handling of simulations. You must set up simulations as if you were developing respondent data, so that the simulation file looks like a data file, filled with zeros or fictional values. This is more work than CBC's straightforward procedure, which requires simple changes to a specification file. The makers of Ntelogit are at work now on a revision to their manual that should make the simulation process in this package more accessible.
CBC keeps much of its inner workings discretely out of sight. You can view the data and the design files, but you do not need to do so. Also, CBC takes care of collecting and aggregating the data with a minimum of help. But to use CBC effectively, you still need to know something about specifying discrete choice models, such as the meaning of interactions between attributes. And as always with discrete choice, you will need to be alert to the possibility that a model can run, and can appear significant, but still will not make any sense. DCM almost always requires more attention to the final model than other analyses, such as conjoint.
CBC represents an enormous stride in making DCM analysis more accessible, just as Ntelogit represents a huge step in bringing analytical power specifically to DCM. For all its relative ease, CBC still has a few areas which I hope will get some attention. Most significant, it does not allow direct testing for the independence of irrelevant alternatives.
While IIA has not often proved to be a problem in the DCM analyses I have seen, you probably should have some means to know when a failure of this condition is present. The CBC program not having this feature is something like a linear regression program not having the ability to check for correlations between residual and predicted values. Even if you rarely use a test statistic like this, or choose to ignore a problem when it is present, it seems prudent to have access to the diagnostic tool.
Perhaps the salient limitation of CBC is that you cannot test more than nine alternatives simultaneously, and more important, each alternative can only have six attributes or features that you can vary. I hope that Sawtooth will work to lift the restriction on the number of attributes in particular.
If you do not mind the limitations that CBC places on the size of the problem you work on, and want a complete system for DCM that works smoothly and simply, this is the choice for you. If you want the most in analytical and diagnostic power, and can tolerate doing some extra work to set up a DCM study (and particularly simulations), you will find plenty to like in Ntelogit.
The programs
The CBC System (Choice-Based Conjoint)
Sawtooth Software
1007 Church Street, Ste. 402
Evanston, IL 60201
Phone: 708-866-0870/Fax: 708-866-0876
Ntelogit
Intelligent Marketing Systems
12907 97th Street, Ste. 204
Edmonton, Alberta T5E 4C2 Canada
Phone: 403-944-9212/Fax: 403-476-1196