
Editor’s note: Albert Fitzgerald is president of Answers Research, Solana Beach, Calif.
One of the troubling issues with developing products and positioning brands is that determining optimal attributes is difficult. Part of the problem is due to the scale bias of classic research methodologies. People tend to rate everything as important because researchers do not force them to make choices between various attributes. When respondents are forced to make choices, relative importance between attributes becomes apparent and decision-making for optimal attribute mixes becomes easier. A simple methodology forces respondents to make trade-offs so that product design and brand development can be approached with the knowledge gained from a scientific methodology instead of the guesswork - albeit educated guesswork - of a manager.
Classic example
Following is a classic example of how we, as researchers, might go about trying to identify the importance of various elements that could affect our brand. We would traditionally use a Likert scale and ask someone to rate the importance of the attributes shown in Figure 1 to the extent that they would affect one’s decision on which brand to purchase. What we would typically get is answers like what we see in Figure 1, where many, many items are rated very high.

We get a lot of 4 and 5 ratings on a 5-point scale. Essentially what we see a lot of times is that virtually everything is rated as important. One reason this happens is because we do not force anyone to make trade-offs. We end up with relatively little difference in ratings for the elements that predict brand choice.
This becomes a serious problem when analyzing our results. We as researchers cannot determine which of our image attributes is most important in determining which brand to buy.
Besides the common problem where “everything is important” we also commonly find that some respondents never choose either end of the scale. These respondents never think anything deserves a rating of a 5 nor do they ever use the lowest point on the scale. We call this end-point avoidance. This clearly poses a problem: Do these respondents really believe that nothing is very important or do they simply use the scale differently than their peers?
We have seen cultural differences as well. In Japan , for example, nearly all ratings are lower - irrespective of the issue - than in the U.S. Do the Japanese care less? Is nothing very important to the Japanese? That is hardly the case. It is simply that Japanese culture rarely rates anything a “top box.” This underscores the need for a solution to the myriad forms of scale bias that make identification of brand preference so challenging!
Not equally important
There is a methodology which forces respondents to make trade-offs, so that everything is not equally important, regardless of whether the respondent uses the ends or the middle of the scale. This approach eliminates all scale bias. Let’s look at an alternative way of asking the same question. We will call this a choice task (Figure 2).

I might say that trust is the most important and reliability is the least important. This is a simple choice task: easy and quick to implement. Respondents generally complete three-quarters as many choice tasks as there are items to rate. In our output example in Figure 3, we list 12 attributes. We would require approximately nine choice tasks in order to be able to derive ratings for all 12 attributes. Our experience has shown that this methodology takes about the same time to implement as if we had respondents rate all 12 attributes on a 1-to-10 Likert scale. Attributes can be grouped pair-wise, in groups of three, four or five. Four is typically the most efficient. A computer-generated design ensures that each of the attributes shows up in several of the choice tasks and is matched against different attributes each time - this eliminates order bias.
It is often said that there is no such thing as a free lunch. Well this methodology is as close as one can get. While back-end analytics are required after the data is collected, using a choice task rating methodology takes no longer for a respondent to answer on a survey than if the respondent had rated our image attributes, one at a time, on a five-point Likert scale.
Better information
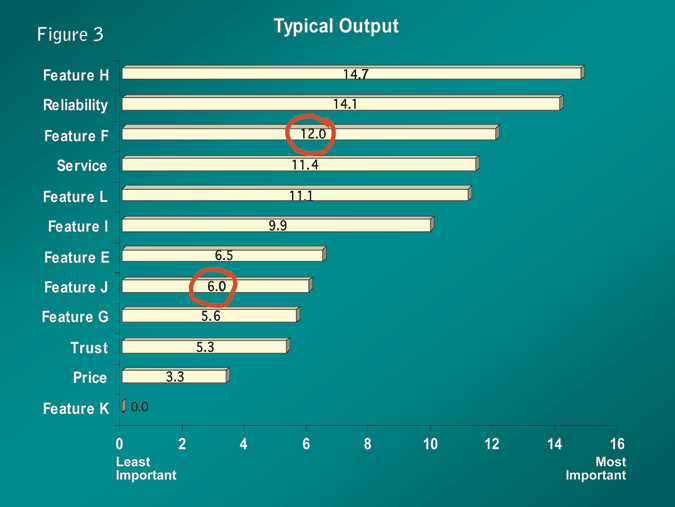
Figure 3 shows the kind of output we would expect to get and it is very easy to interpret - much better information than what we get from your classic Likert scale. On this type of scale the sum of all the rating scores equals 100. If we look at the bar chart we see that one of these attributes (Feature J) is rated as a 6. Feature F is rated as a 12. One thing we can say here is that anything rated a 12 is twice as important as anything rated a 6. You cannot say this with Likert scales: it is not valid and true. The reason this is valid and true using choice task ratings is because we generate ratio data with an absolute zero point. We can compare attribute scores against other attribute scores on the scale. If one number is twice as large as another, it is twice as important.
To summarize the benefits of choice task ratings:
- Choice task ratings are free from scale bias.
- Choice task ratings provide better discrimination among items.
- Choice task rating items are measured on a common ratio scale.
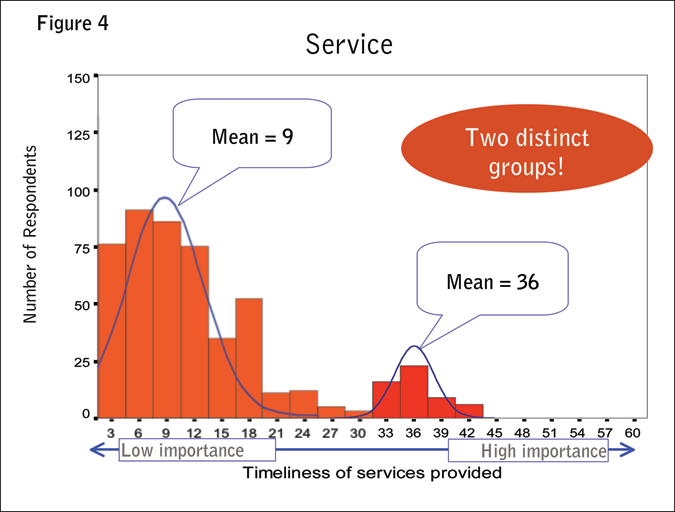
What were the results we found when we actually implemented this methodology? Figure 4 shows real data we obtained from a study of 500 respondents. In the histogram, the height of the bars is represented by the number of respondents for each importance scale rating. The first bar on the far left extends up to 75. That is because 75 respondents fall into the first bar. On the X axis we have the relative importance of service when selecting a given brand. One of the valuable insights we can glean from this information is that we find two distinct groups of respondents. This is great for us because we can see that we have one group with a mean around 9 and another group which found service much more important with a mean around 36. These two groups would be very difficult to identify and discover if we were using a Likert scale which had a 1-10 rating because in many cases, people only use the top half of the scale, if that much. Also we would never see this level of discrimination, or this level of difference between the various scores.
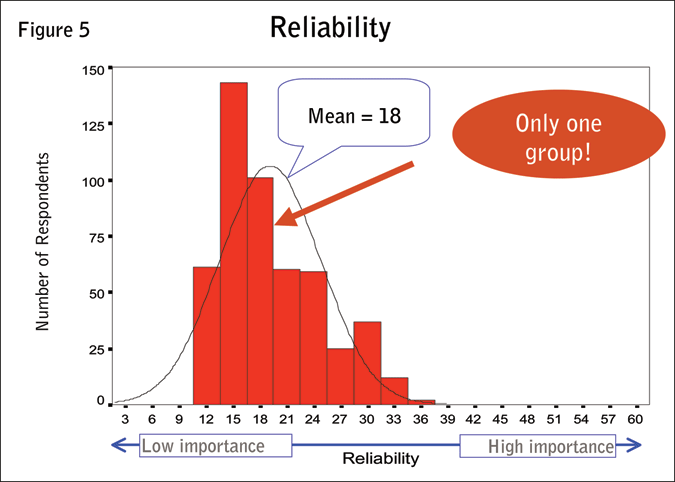
What we see on another item, reliability, is that there is only one group. The mean is 18 and all of the responses cluster around the mean (Figure 5).
When we take a look at trust, and this is the actual data from a study that we implemented, we found three distinct groups of respondents: one group with a mean around 5, another group with a mean around 20 and the last group with a mean around 50 (Figure 6). This was extremely valuable to our client. We were able to analyze this data by running simple crosstabs to identify who these people are. We were able to compare the three groups and identify demographic differences.

From Figure 3 (showing “Typical Output”), we might assume that trust is relatively unimportant in the brand choice decision. This does not mean that trust should never be emphasized. There is a group of individuals who value trust highly: the group has a mean rating of 50 for the trust attribute - 10 times higher than the mean of all respondents. Since these individuals are unique demographically, trust should be emphasized when targeting individuals whose demographics indicate they value trust. If this segment of the market is large enough, separate marketing efforts or new services geared towards them may be worth implementing.
By understanding the relative importance of product and brand features, managers can focus their efforts on attributes that are relevant and important to their customers. Since they can be confident they have identified what is important, less time is spent worrying about whether or not they are focused on the right attributes.
Technical note:
The choice task rating methodology is sometimes referred to as best-worst ratings or maximum-difference ratings (max-diff). The methodology is a sophisticated multivariate way of deriving ratings based on respondents trading off features in choice tasks. Recent advances utilize hierarchical Bayes estimation (HB) to derive the beta coefficients or actual rating scores. Hierarchical Bayes estimation employs an iterative Markov chain Monte Carlo to arrive at highly accurate rating scores. Early, more “basic” max-diff methods did not use HB to estimate resulting rating scores. We strongly recommend using HB estimation methods for deriving model parameters due to the higher accuracy and lower error factors that typically result.