Paul Schrock is the group manager of Data Systems for Walker: DataSource. a division of Walker Research. Inc. headquartered in Indianapolis, Indiana . He has been in the Walker organization for nine years and has previously held the positions of tabulation services manager and data processing manager. Prior to joining Walker Research, Mr. Schrock taught mathematics and statistics at the secondary and college levels in the Indianapolis area.
Data weighting (also known as sample balancing) is an under-utilized technique within many segments of the survey research industry. In addition to the lack of use, there are instances of improper use that may lead to erroneous conclusions. The following descriptions and examples may foster more effective use of this powerful technique by researchers in many types of organizations.
In its simplest form, data weighting is nothing more than the multiplication of survey observations by one or more factors to increase or decrease the emphasis that will be given to the observations. The troublesome aspect of weighting is related to the selection or calculation of the weighting factors. As analysts, we may get ourselves into difficulty by not being careful in the specification of the weighting scheme. The specifications must be defined in terms of the overall objective: What is the purpose of the weighting? In most situations, the obvious answer is that we would like our survey data to be representative of the "real world." The immediate follow-up to the first question is another: In what ways are the data to be representative of the population? The answer to this question should lead us to select an appropriate weighting technique.
In its not-so-simple form, data weighting involves setting targets, which then leads to the calculation of factors. The researcher who uses a target percentage as though it were a factor is heading for a most unpleasant encounter with his/her client. Let's walk away from this nightmare for a moment and review some of the commonly encountered situations where weighting is appropriate.
Cost containment by reducing the number of interviews required in a survey is a very compelling reason for using weighting. In order to maintain a desired precision level, certain quotas may have been established which are not in proportion to the population. Low-incidence segments of the population can be over-sampled without doing extra interviews within the easy-to-find segments of a representative sample. In other instances, uncontrollable response rates may create situations where the data must be weighted to compensate for one or more segments of the population which are under/over represented in the sample. There are even occasions when specific proportions are desired simply for comparability to other surveys.
There are also many legitimate ways to represent a single observation. Under the “one person, one vote” approach, each observation would be tallied as a single case. Most of us will find occasions, however, when we would rather let each observation be counted in terms of dollars spent, or items purchased, or number of persons in the household, etc. These objectives lead us to select factors from within the data itself rather than setting a target for which a factor must be calculated.
Most of the tabulation and analysis software packages available are capable of handling weighted data, although there is considerable variation in how hard one has to work in order to achieve the desired results. The better packages allow the user to specify either target weighting or factor weighting with a short series of statements defining the data elements involved and the values to be used. It is also possible within most of these packages to capture the final weighting factor and store it as a field in the data record. This makes it possible to export the data onto other systems while retaining the factors for subsequent processing.
Let us now turn our attention to an example which will be used to illustrate several different approaches to weighting the same set of data. The effects of weighting can be quite dramatic under certain circumstances.
Once upon a time, there was a client who had exactly 120,000 customers. This client asked WYSIWYG Research, Inc. to conduct a survey of its customers to determine the overall level of satisfaction with the services provided by the client company. The client categorizes its customer base as Light, Medium or Heavy users, based on the number of times per month that the company's services are used by the individual customer. For the purposes of this example, we will say that the company's records show that there are approximately 72,000 users who fall into the Light category, 36,000 in the Medium classification and only 12,000 who qualify as Heavy users. Let us also assume that these same records indicate average numbers of service occasions per month of 2.5, 10.0 and 30.0 for the three categories respectively.
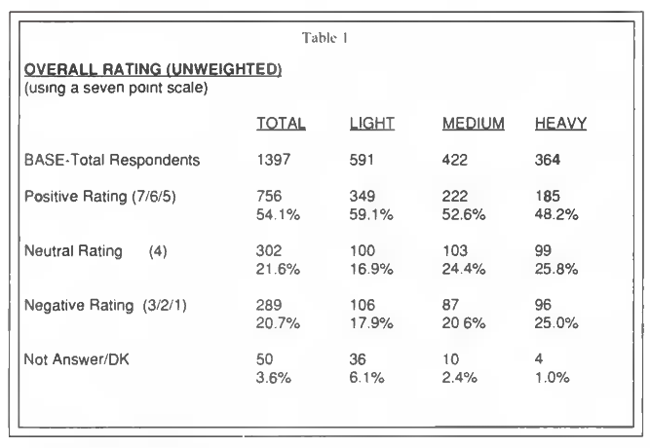
The task of WYSIWYG Research was to gather a minimum of 384 interviews within each of the segments of the customer population (for statistical precision purposes). A representative sample drawn from the population would generate 2300 completed interviews in the Light category by the time 384 Heavy users had been surveyed, assuming equal contact ratios, etc. Thus, a stratified sampling plan was implemented where equal numbers of potential respondents were randomly selected from the three usage categories prior to interviewing. To avoid bias resulting from external influences during the interviewing period, the instructions required that dialing continue in all three sample categories at an equal rate until the last quota was filled. Differences in the availability and refusal rates caused the Light and Medium quotas to be exceeded by the time the Heavy quota was filled. Table 1 illustrates the outcome of the survey with respect to the Overall Satisfaction question on an unweighted basis.

Upon reviewing the initial survey results, the client expressed a desire to see the data presented as though a complete census of the customer population had been accomplished. This objective lead WYSIWYG Research to recommend a weighting scheme that would use the 1397 interviews to represent the population base of 120,000 in the proportion to the known distribution of Light, Medium and Heavy Users. The appropriate targets were fed into the tabulation system resulting in the presentation shown in Table 2.

Notice that the percentage distribution of positive, neutral and negative ratings have not changed within the individual user categories. The distribution of responses within the total grouping has, however, taken on a new perspective.
This presentation of the data would be useful to corporate managers who are interested in monitoring the satisfaction levels within the customer population in total where each customer is given equal importance, without regard to size. It is also possible within this presentation of the data to identify areas for closer scrutiny if the overall rating appears to be driven by a particular segment of the customer base. (Note: caution must be exercised when using statistical tools to identify significant differences that are apparent in weighted tables. More on this later.)
This presentation of the data might also be useful if account responsibilities are assigned on the basis of size. The manager responsible for overall customer satisfaction might convey a greater sense of urgency toward the persons responsible for the larger accounts than he/she might have if the data had not been weighted in this way.
In the course of working with the client, WYSIWYG was asked to identify the sources of overall dissatisfaction. In addition to recommending a "key driver' analysis of specific service attributes in relation to the overall rating, it was recommended that the data be reviewed for statistically significant differences between the usage categories. A slightly modified weighting scheme was implemented to facilitate this investigation. Rather than weighting the data up to the total population targets, proportional targets were specified while the base number of interviews was held constant. Display of a second base line showing unweighted bases was requested through the software with the output shown here as Table 3.

Notice how the percentage distributions (which are calculated using the weighted base) have not changed from what was seen in Table 2. It is only the absolute numbers (weighted base and frequencies) that have been scaled down to match the true number of observations contained in the data. This presentation allows the analyst to view the survey results as if the sampling plan had been implemented in proportion to the population while at the same time having a sufficient number of observations (the unweighted bases) in each category to permit statistical inferences with the desired level of precision. A simple z-test to compare the proportion of positive ratings of the usage categories can be accomplished using the weighted percentages and the unweighted bases. (Again, the reader is cautioned that not all statistical comparisons are appropriate using weighted data and that a thorough understanding of the theory is required prior to "running wild" with the data.)
As is the case in many service industries, the small proportion of Heavy users accounts for a large share of the business volume. In recognition of this fact, it was decided that another weighting scheme should be implemented to represent the survey results in proportion to the number of service opportunities that occur on a monthly basis. This approach requires the use of factor weighting. The customer database was accessed to generate a record for each customer included in the survey which would show the average number of service occasions over the Past three months on a customer by customer basis. However, it is still true that the sample was not balanced in proportion to the customer population. Thus, the weight established for each respondent as shown in Table 3 was retained and used as a pre-weight in the process of generating the results shown in Table 4. The net effect of this approach is that the data are first balanced to match usage category proportions and then multiplied by the number of service occasions represented. The final factor developed by the computer is the product of the two individual factors known for each respondent.

Notice how the percentages of positive, neutral and negative ratings in the total column have changed again. The 56% positive rating has slipped back to a 52.1% rating. This presentation of the data helps to focus attention on the customers who generate the most business volume.
In some ways, the examples we have reviewed might add to the confusion over the best ways to analyze survey results. On the other hand, it is hoped that all of us will become more effective in our roles as we regularly use the power of data weighting in the process of conducting survey research.