In the recent history of marketing, competition in the marketplace has become more and more intense as new products, product refinements and line extensions have proliferated. Demographic profiles and levels have changed dramatically, with change as the expected norm. Levels of income, education and age have grown geometrically. Geographic distributions are in a state of flux. An accelerated growth of actual and perceived needs has kept pace with the expansion of lifestyles. Consumption horizons have broadened dramatically and the consumer is demanding an ever-widening range of wants.
These marketing trends are mutually reinforcing so that the expansion of one contributes to the acceleration of the others. The intensity of competition must keep pace with the growth of the demand. The marketers are constantly "on the spot" to gain insight into the consumer process of change so that their products can maintain existing and gain new positions.
As a result, marketers must look for the subgroups and submarkets which will add to a sharper definition of the consumer needs and wants. They must find ways to reach and appeal to these diverse groups. They must tailor their product and their message to achieve the "sale."
It is not sufficient for marketers to simply look at the demographics of the consumer and to get a picture, as accurate as necessary, of consumption patterns of the individual and family. They must understand the reported needs, attitudes, perceptions, lifestyle and psychological profiles of the consumer in order to gain the required response to marketing efforts.
Market segments
Their first task, therefore, is to derive meaningful discriminating market groups and to decipher the characteristics that make the discrimination actionable. These groupings have been identified with the marketing labels, segments and/or clusters. They must isolate these groups in which the consumer members are as homogenous as possible, while simultaneously being different from other groups.
In order to achieve this goal, the marketer must rely on highly sophisticated statistical and mathematical methods. In most cases, the marketer is relatively unsophisticated in the mechanics of performing these operations. The marketer is usually only concerned with the bottom line, the resulting groupings, while taking the technical validity for granted. However, lack of sophistication not withstanding, the marketer is responsible for the conceptual integrity of the research.
The selection of the appropriate grouping technique requires the understanding of the basis of the methodology. Too often, the selection of the technique is based upon exogenous criteria (i.e., "Do we have the program? "Will the data fit within the limits of the program?" "Does anyone know how to use the program?" And sadly enough, "I've always used this technique and it will do the job! ")
There exists in the selection of the existing popular methodology, two very different criteria. Each is based upon the internal structure of the data. The diversity of these two measures cannot be ignored when deciding upon the method to be used. This diversity is manifested in the distinct labeling of the techniques. They are:
- Segmentation. This is based on the relationship between subjects within a group definition. This relationship seeks to maximize the "correlation" measure between group members.
The groups are appropriately called segments. The technique used to achieve this segmentation is Q-Segmentation Analysis, which is a factor analytic-based technique. - Clustering. This is based on the proximity of group members to one another. The method seeks to minimize the distance between group members while maximizing the distance between the different groups.
These groups are called clusters. The technique used to achieve this clustering is the K-Means Analysis, which is a form of variance reduction methodology.
The programs used to compute these two different analyses are insensitive to the differences in the data. The selection of the method is the decision of the researcher. The program will obediently perform its task on the data it is given. The results, however, could be dramatically different.
Before we get into the discussion of the dilemma of making the selection, let us illustrate the difference with a very oversimplified example.
Isolating subgroups
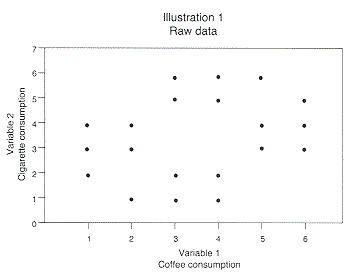
Suppose we have a problem in which only two items (variables) have been measured and we are interested in isolating two subgroups. The scales will be 1-6 and the raw data is distributed with one concentration around 13 for both variables and another concentration around 3-6 for both variables (see illustration 1).
 |
If we were to perform the two techniques on this set of data, we would get the results for clustering as shown in illustration 2 and for segmentation as shown in illustration 3. Both techniques would result in a unique assignment of each case to one group or the other.
 |
What do these illustrations tell us? The clustering process tells us: Cluster 1 is where variable 1 is low while variable 2 is also low; cluster 2 is where variable 1 is high while variable 2 is also high. Both of these groups are dependent on the location of the variables while they are independent of the relationship between the two variables.
 |
The segmentation process tells us: Segment 1 is where variable 1 is consistently higher than variable 2; segment 2 is where variable 1 is consistently lower than variable 2. Both of these groups are dependent on the relationship between the groups and independent of the location of the variables.
The question is: Which is right? The answer is: That depends! Therein lies the dilemma.
First the reader is cautioned that this is a case in which the data has been constructed to illustrate a point. The issue has been sharpened by the structure of the data. In the "real life" situation, the data will not be as sharp and the issue will be more diffuse.
Again, for the purpose of illustrative understanding, let us flesh out these variables and give them some substantive meaning.
Let us say that variable 1 is the scale of coffee consumption and variable 2 is the scale of cigarette smoking. The clustering tells that people who are low coffee consumers are also low cigarette consumers. The two clusters will isolate markets in which one high/low level accompanies the other. Are we selling to a market level? (Do you smoke and drink coffee lightly/heavily?) That is the question!
High or low consumption
The segmentation tells us that people's cigarette consumption is either higher or lower than their coffee consumption. Are we selling to a consumption tendency? (How much more/less do you smoke/drink coffee?) That is the question.
Which one will we use? The one that answers the marketing question at hand. The main point is that they are both technically accurate and substantively valid, depending on the marketing question. Market groupings, be they segments or clusters, are never inherently defined. They will be useful only as far as they will answer the marketing question. For the most part, behavioral questions will be level-oriented while perceptual questions will be correlation-oriented.
The next step is up to the researcher. The questions must be understood conceptually. The research must be designed to collect the pertinent data. And finally, the appropriate program to do the analysis must be selected.
The programs to do these analyses are available from a number of sources: Software firms, consultants and universities. We will address ourselves to the PC market where much of the emphasis is going today.
The K-Means Cluster methodology is available for the PC from several sources: SPSS/PC+ from SPSS Inc., Chicago; SYSTAT, from SYSTAT Inc., Evanston, Ill., and PC-MDS from Brigham Young University, Provo, Utah. The Segmentation methodology is available from Pulse Analytics, Inc., Ridgewood, N.J.
As a final footnote to the dilemma, we must acknowledge that exogenous conditions may still play a part in the use of the techniques. One significant condition is that all the K-Means programs mentioned here are handicapped by the limitation on the number of variables and cases that they can handle.
My experience shows that the usual research project is ambitious beyond the limits of these programs. Therefore, the researcher should try to use data reduction methods rather than select an alternative method by default.