Editor’s note: Susie Li is manager of customer targeting and planning at Sanofi-Synthelabo, a New York pharmaceutical firm.
Making marketing strategies is a complex process requiring research, judgment, and creativity. Marketing research helps marketers establish an objective (or, simulated/virtual) marketplace to understand their customers and their products, or answering questions like: How do my customers use my product? What are the strengths and weakness of my product relative to my competition? Where does my product fit in the overall market consuming such products? Who are the targeted customers for my product?
Once this structured framework is established and understood, it then becomes a guide and analytic platform for creative strategists to design innovative, targeted strategies (to fill the gaps, or to raise the existing product to a higher ground, etc.).
A comprehensive product research project, namely, a portfolio analysis, should provide all the following information:
1) What (is the overall competitive market structure for this product)? Systematically map the entire market, partition it into a competitive hierarchy by studying consumer preferences, consumers’ product usage, product substitution and switching behaviors in the past.
2) Why (do consumers buy our or our competitors’ products)? Study the desired benefits of products and fulfillment of those benefits, from the perspective of the consumers.
3) Who (are the customers for our or our competitors’ products)? Develop consumer segmentation based on their lifestyle, life cycle, and product usage pattern.
4) How (do we better manage or market our product)? Identify consumers’ unmet needs and desirable product features or growth/niche opportunities; optimize pricing or promotional strategies; market to targeted customers or segments; create well-defined, consumer-focused product-positioning strategies to maximize volume and profits.
Steps 1, 2, and 3 are intensive analytic work calling for various quantitative or qualitative models, whereas Step 4 is a guided creative process. Perceptual mapping is one of the many techniques used in the analytic steps, and an extremely popular one.
Its beauty is in its graphical display: Simpler to interpret than a listing of numerical results, it quickly points to potential relationships, connections, and patterns in the data. Its deficiency is that the graph is only an approximate representation of the real data, because of the amount of data condensation/transformation the procedure requires. Therefore, perceptual mapping should not be used alone to reach any conclusions, and must be accompanied by other mathematical means to verify its findings. In general, perceptual mapping is a powerful tool for exploring data, and for coming up with hypotheses.
Consumer researchers especially appreciate the feature of perceptual mapping in compacting complex consumer behavioral data (usually a vast amount of multi-dimensional psychometric measurements) into a concise, easy-to-show format. Simple techniques like this not only help researchers avoid taking the wrong paths, but also open them to fresh possibilities not obvious from traditional methods.
There are three ways of producing perceptual maps, although most people are familiar with only one: the MDS map. The three types of maps are produced by three different techniques and have different usages:
1. Preference map
2. Multidimensional scaling (MDS) map
3. Correspondence map
Each map requires a different view of the input data, and the maps are used to study different aspects of the marketing problem. In the following sections, I will explain in general how to create the preference map and the MDS map, how to examine the results, and how to use the results to generate new ideas. Then I will present a correspondence map example in more detail, linking the input data with the output map, and a creative (somewhat ad-hoc) application of the correspondence analysis.
1. Preference map (for study of consumer preferences)
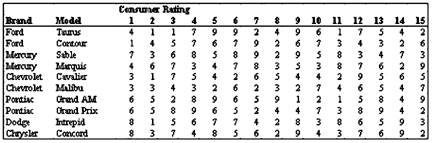
A basic preference map shows consumers’ preferences for a set of products. It is more useful than presenting a table of mean ratings. In a typical preference analysis, consumers are surveyed for their preferences for a set of products. For example, 15 consumers are asked to rate their preferences for 10 U.S.-made cars on a rating from 1 to 10 (1 is the least preferred, 10 is the most preferred).
The data is shown in the table below. Preference analysis performs a principal component analysis on the rating data, and then plots the first two principal components from the analysis to create an approximate two-dimensional display of the consumer preferences for the 10 cars.
 |
 |
Reading the basic map: The points on the map above are cars. The placement of the points has everything to do with consumers’ ratings. The arrows are the individual consumers who rated the cars. Cars that project farther along a consumer’s vector are more strongly preferred by that consumer.
To interpret the two axes (i.e., the principal components or the dimensions) can be tricky. The first thing to remember is that cars at the positive end of either dimension are preferred to those at the negative end. Dimension 1 is usually related to consumers’ overall preference. However, it takes judgment to interpret the meaning of Dimension 2, usually by observing the placement of the cars and knowledge of those cars. Dimension 2 in the car example appears to be related to vehicle ride or fuel economy (we will confirm that later).
Variation
Sometimes, in order to confirm the meaning of Dimension 2, a researcher may ask the consumers to rate three more attributes, like vehicle ride, miles per gallon, and reliability. The researcher then projects the new attribute information onto the original scatter plot of cars to produce an “ideal-point” model of preference mapping.
The overlay plot shows you which cars are closest to the ideal level of vehicle ride/miles per gallon/reliability. For our car example, Marquis has the shortest distance from the ideal point for the attribute Ride, therefore closest to ideal ride; similarly, Taurus is closest to the ideal point of Reliability; Contour is closest to the ideal point of MPG.
For insights and ideas, ask the following:
- What products do most consumers like?
- Where is my product positioned relative to my competitors’ products?
- What new consumers should I target for my product?
- What new products should I create for consumer segments where there is interest but currently few products available?

Comparing the first map with the second map, you can postulate that there is a segment of consumers interested in upscale cars which are reliable and ride well (consumer vectors pointing to Ride and Reliability, where there is no car). These are potential buyers for luxury cars which will not break down easily (think Lexus or Acura).
2. Multidimensional scaling map (for analysis of product competitiveness)
Multidimensional scaling is a graphic technique for analyzing the similarities (or dissimilarities) between products. It is not meant for studying consumer preference, but for analyzing competitive positioning of the products in the minds of the consumers. In this exercise, you will create an approximate plot of product points such that distances between points mirror the degree of their similarity. You can also use this plot to learn something about the unknown attributes that may underlie consumers’ perception of these products’ similarities.
The data: For a multidimensional scaling survey, it would be ideal, but highly impractical, to ask every consumer to rate the degree of similarity (or dissimilarity) between all possible pairs of products, because the number of pairs of products to rate would be too large if there are many products. Alternatively, each consumer is asked to place the products into groups of similar products. Consumers can decide as many or as few groups as they like (see chart below).
 |
Each row of the data contains the groups of similar cars perceived by a particular consumer. For example, Consumer 2 created three groups of similar cars: group one contains Taurus, Contour, Grand Prix; group two contains Cavalier, Intrepid, and Concord, and so on.
Multidimensional scaling performs an initial principal component analysis of the original data, and then improves on the solution iteratively. When the solution can no longer be improved, the procedure stops and produces an optimal two-dimensional map of product distances (below).
 |
Reading the basic map: Points on the map are actual products. Points close together are perceived by the consumers as being similar. In general:
- Points that are closely clustered together are competing against each other.
- Points that share the same point or are almost on top of each other are substitute products for each other.
- Study (or estimate) the hidden attributes that describe the dimensions of the plot. These attributes/dimensions can help explain how consumers judge the degree of similarity between products. You may learn something from the consumers to redesign your product for better perception.
- If the dimensions are not directly interpretable then perhaps the directions as pointed to by the products, through the space defined by the dimensions, may be interpretable.
Again, for insights and ideas, consider the following:
- What products are substitutes for each other?
- What products compete with each other?
- How do consumers view the competitive positioning of my product? (Which products compete directly against my product? Which products can my new product hope to compete against?)
- What is the consumers’ overall perception of the competitive marketplace?
- How should I reposition my product to better compete in this market?
3. Correspondence map to explore information in any frequency table
Correspondence analysis is an ingenious device to explore the associative relationships and clustering patterns in the frequency data. For example, you can use the correspondence map to examine the association between a categorical variable that identifies a group of customers and another categorical variable that distinguishes your product. It is even equipped to display multiple categorical variables simultaneously (such as in multi-way tables of frequency), each having a large number of levels, although with some sacrifice (i.e., the distances between all points in the plot become meaningless).
Simple correspondence map
The following two-variable frequency table of car by income shows these associations by visual inspection:
- the lower income level is associated with Cavalier and Contour;
- the middle income level is associated with Sable;
- the upper income level is associated with Intrepid, Grand Am, and Grand Prix.
|
Car Model |
Income | |||
|
Frequency |
Lower |
Middle |
Upper |
Total Row |
|
Dodge Intrepid |
2 |
7 |
16 |
25 |
|
Chevrolet Cavalier |
49 |
7 |
3 |
59 |
|
Pontiac Grand AM |
4 |
5 |
23 |
32 |
|
Mercury Sable |
4 |
49 |
5 |
58 |
|
Ford Contour |
15 |
2 |
5 |
22 |
|
Pontiac Grand Prix |
1 |
7 |
14 |
22 |
|
Total Column |
75 |
77 |
66 |
218 |
Using these frequency counts, we can construct row and column profiles (see above): row (or car model) profiles are simply row percentages divided by 100; similarly, column (or income) profiles are column percentages divided by 100.
These row and column profiles can be thought of as points in a higher-dimensional space. For example, the six-row (car model) profiles form points in three (column- or income-) dimensions:
|
|
(Lower, |
Middle, |
Upper) |
|
1. Intrepid |
(0.08, |
0.28, |
0.64) |
|
2. Cavalier |
(0.83, |
0.12, |
0.05) |
|
3. Grand AM |
(0.13, |
0.16 |
0.72) |
|
4. Sable |
(0.07, |
0.84, |
0.09) |
|
5. Contour |
(0.68, |
0.09, |
0.23) |
|
6. Grand Prix |
(0.05, |
0.32, |
0.64) |
Similarly, the three column (income) profiles form points in six-row (car model) dimensions.
|
|
(Intrepid, |
Cavalier, |
Grand AM, |
Sable, |
Contour, |
Grand Prix) |
|
1. Lower |
(0.03, |
0.65, |
0.05, |
0.05, |
0.20, |
0.13) |
|
2. Middle |
(0.09, |
0.09, |
0.06, |
0.64, |
0.03, |
0.09) |
|
3. Upper |
(0.24, |
0.05, |
0.35, |
0.08, |
0.08, |
0.21) |
Note that to accurately describe these profile points in a plot, we would need at least a three-dimensional plot (lesser of the three columns and six rows) - which would be impossible to fathom with human eyes. We can, however, use correspondence analysis to perform a variation of principal component analysis appropriate for categorical data on these row and column profiles, and retain only the first two dimensions (or principal components) for plotting an approximate representation of the row and column profiles.
 |
Each row or column profile is now displayed as a point in this plot. The plot shows the association between various levels of the row (car model) profiles with those of the column (income) profiles. However, owing to data transformation, absolute distances between the row and column profiles have lost meaning. We can only examine the “cluster pattern” and “relative distances between clusters.” The more clustered the points are, the more associated the row or column levels are with each other; conversely, the further apart the clusters are from each other, the more distinct their relationships are. This correspondence map graphically confirms the relationships we have observed earlier.
One word of caution: Association does not imply causation. While the points appear clustered together, they are not necessarily linked in a cause-and-effect manner. For example, we know that certain income levels tend to own certain cars from our correspondence map, but we can’t be sure if those income levels caused those cars to be purchased. A correspondence map can describe a phenomenon, but cannot tell if one variable causes the other. You will need mathematical modeling, like logistic regression, to investigate the causal relationships.
Multiple correspondence map
Things get a lot more interesting when you try to make sense of multi-way frequency tables. Looking at a crosstabulation to figure out the relationship between two variables is easy. Beyond that, the task becomes much more difficult. For example, if you have four variables, you may have to examine six crosstabs to guess at the intertwined relationships. Multiple correspondence analysis is especially effective at simplifying these complex multi-way tables, and making them into a single display similar to that generated by the simple correspondence analysis (except there will be more points on the map). You read the multiple correspondence map much the same way as you would a simple correspondence map.
An example of using a simple correspondence map to solve a puzzle
Situation: The marketing department of a major car manufacturer would like to refine their customer-targeting strategy. A consumer segmentation was done by a department based on consumers’ lifestyle demographics only, without regard to the types of cars they drive. The marketing department wants to know what types of cars these segments are most likely to buy without redoing the segmentation.
Solution: To quickly find out the types of cars most likely owned by the individual segments, the analyst quickly tabulates the frequency of car types by consumer segments. The table is shown below.
 |
A simple correspondence map (below) is produced based on this frequency table.
 |
This plot provides the analyst with some valuable insight into the relationship between the types of cars and segments:
- Segment 4 tends to own performance-types of cars, be they luxury or popular sporty cars. This is a young, stylish and performance-conscious group of customers.
- Segment 6 tends toward sedan types of cars, be they luxury or popular sedans. This segment values the comfort, stability, and safety of a traditional large car.
- Segments 2 and 3 tend to own station wagons or vans. These segments are family-, children-, or cargo-oriented, and value cars with ample luggage/cargo space.
- Segment 7 prefers SUVs, be they luxury or popular SUVs. This segment of consumers may like the dominant, rugged, and protected road feel of the SUV.
In this example, car personality also matches nicely with owner personality (which is described by the demographic characteristics of the relevant consumer segments), thereby increasing the “face validity” of this analysis.