Editor’s note: Kristin Cavallaro is knowledge and data analysis specialist at Survey Sampling International, Shelton, Conn.
Effective global research that gathers accurate consumer and market information is essential for building successful global sales, marketing and expansion strategies. With the growth of the Internet and social media around the world, it has become easier and less expensive to conduct global research via online surveys. The result has been an increased volume of online global research projects.
As we depend more on insights gathered globally online, it is critically important that we understand what our survey respondents really are saying when they give us an answer. That means we must truly understand the countries and cultures of our research participants. We already know that people around the world speak different languages, practice different religions, eat different foods, celebrate different holidays, buy different brands and watch different TV shows. These are all factors that market researchers consider when designing international online research studies. We translate surveys into the appropriate languages, add appropriate demographic questions and set appropriate quotas. The survey is then good to go, right? Not necessarily.
There are many differences we need to account for in the areas of global research and questionnaire design that we typically don’t consider, because we are victims of what we do not know. These differences include the social and cultural variations that drive respondent thought processes around the world. To account for the variations, we must go far beyond simply making sure brand names are localized and proper grammar is used.
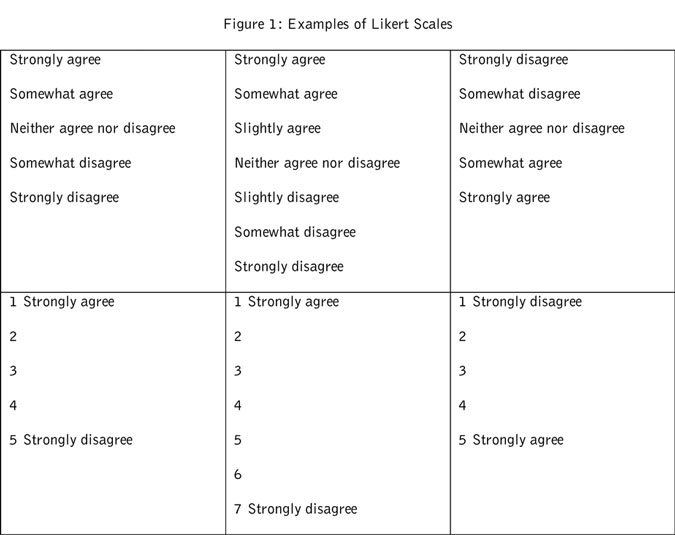
One key difference among global research participants that many market researchers aren’t aware of is the variations in how people from different cultures respond to different types of questions and response options. Scaled questions offer a clear example of these variations and their impact. The idea that the Likert scale is universal in application is a misconception. In fact, the way we present the Likert scale can yield different results within and between cultures.
The Businessdictionary.com defines the Likert scale as a “Method of ascribing quantitative value to qualitative data, to make it amenable to statistical analysis. Used mainly in training course evaluations and market surveys, Likert scales usually have five potential choices (strongly agree, agree, neutral, disagree, strongly disagree) but sometimes go up to 10 or more. ... Named after its inventor, the U.S. organizational-behavior psychologist Dr. Rensis Likert (1903-81).”
In practice there are many variations of the Likert scale (Figure 1). These variations can range from verbal to numeric and from scales of five to scales of 10 data points. The five-to-seven-point scales are most common for marketing research surveys.

Members of academia have conducted some research on the optimal Likert scale. Most have found it difficult, however, to isolate which form provides a higher degree of validity and therefore tend to focus on reliability.
Understand the differences
SSI decided to perform its own test on Likert scales. The goal was not to find the Holy Grail of Likert scale formation in each country but to understand the differences associated with the different ways of presenting the scale to respondents around the globe.
To achieve our objective, we launched a seven-country study which tested a five-point Likert scale presented in two different manners. The scales we chose are those most commonly used in market research studies worldwide. The first was a verbal scale in which all points were defined in words (i.e., strongly agree, slightly agree, neither agree nor disagree, slightly disagree, strongly disagree). The second was presented a numerical scale where only the first and last options were anchored or defined (1 = strongly disagree, 2, 3, 4, 5 = strongly agree).
The questionnaire included six different sections: self-comparison to set reference groups; women’s rights; importance of cultures and traditions; dependent versus independent thought processes; public appearance; and acceptance/likelihood to purchase a new product concept. Questions were grouped into like subjects, enabling us to conduct reliability testing by analyzing how well the responses to these questions fit together within topic areas.
We used Cronbach’s Alpha reliability test, which essentially enabled us to look past the “noise” that exists when using scaled data. (The test is explained in more detail later in this article.) The countries included in the study were the U.S., the U.K., Italy, Japan, China, Brazil and Mexico.
One piece of research that provided inspiration and guidance for this project was a paper by Heine, Lehman, Peng and Greenholtz on the cross-cultural comparisons of subjective Likert scales. The paper’s objective was to determine a pattern in cross-culture responses to questions, specifically between Asians and North Americans. It directly related to SSI’s research on the use and analysis of Likert scales across different cultures.
Again, we were not looking to find fix-all results from this study, as many have tried and failed to do before us. Instead, the focus was on findings that would provide a new and deeper understanding of cultural differences. Our results give us interesting insights into how the formation of a question and its response option can affect study outcomes. They also provide a foundation for further research into how cultural differences impact findings.
Did the various Likert scale presentations produce different data? Yes, there were definite differences in results even within the same country. Our research verified that that the way we presented the Likert scale did in fact produce different data. The table of means (Table 1) reveals the differences for each question or set of questions. It highlights all the means that were statistically significantly different at a 95 percent confidence level. In addition, we’ve included a top-box table (Table 2) to ensure that our results are not due to satisficing.


For the first set of questions (comparison to reference groups), respondents were asked to compare themselves to their friends and family on intelligence and success. In Italy, China, the U.K. and Brazil, a higher percent of respondents rated themselves smarter and more successful than both their friends and their families in the numeric version of the questionnaire than on the verbal version. In contrast, Japanese and Mexican participants rated themselves smarter and more successful on the verbal version of the questionnaire.
We also found differences across the next set of questions, which asked respondents how much they agreed or disagreed with several statements related to a subject. In almost all cases across all countries, the verbal scale yielded a higher likelihood to agree with the statements than the numeric scale.
So are verbal or numeric scales better? While the results prove that the way we present the Likert scale affects the data, they don’t reveal which version is the most valid. By valid, we mean which set of results is most correct or true. Because we do not really know whether or not our respondents are in fact smarter or more successful than their friends and family, we can only look at which scale type appears to be most reliable - the one that is the better measuring tool.
Conducted a reliability test
To discover which scale is most reliable, we conducted a reliability test, using Cronbach’s Alpha test, which groups the like subject questions together and looks at how closely they correlate or fit together. The test looks at every combination of responses to like-minded questions and determines the correlations between the responses in the data set. It then assigns a score on a scale from 0 to 1. The closer to 1, the more reliable the scale is estimated to be. In Italy, Japan, China and the U.K., the verbal versions of the Likert scales performed better than the numeric scales via a Cronbach’s Alpha test, meaning they had a higher score than the data from the numeric scales.
We also conducted a Cronbach’s Alpha test across the second and third sets of like questions. The first set of questions in this group pertained to women’s rights. As you can see in Figure 2, Italy, China, the U.S., and Mexico performed better with the verbal scales while Japan, the U.K., and Brazil performed better with the numeric scales. These results flip-flopped for most countries with the next section on cultures and traditions, with the exception of the U.S. and Brazil.

Some cultures gravitate toward the center
The paper by Heine, Lehman, Peng and Greenholtz points out a discovery by Chen, Lee, and Stevenson in 1995 that respondents from some cultures tend to gravitate toward the center of the scale more than others. In looking at a simple distribution curve across several questions, we confirmed that finding in our own research.
The tendency to gravitate to the center was particularly noticeable in Brazil when we looked at the verbal scale. Notice in Figure 3 the middle three response options have a similar count when respondents are evaluating a breakfast cereal concept. Now take a look at the numeric scale on this same question. The central gravitation that we saw in the verbal scale begins to disseminate toward the outside, more extreme responses.

This supports earlier findings with Brazil that the numeric scale appears to be stronger than the verbal scale in that country. When we compare this to the U.S. data for the same question, we see the U.S. distribution curve is much more evenly distributed in both the verbal and numeric scales.
There are also thoughts and concerns that some cultures tend to respond more favorably toward concepts and statements than others simply because of their culture - not because they actually prefer the concept. This is true among cultures that tend to be more polite and conscious of others’ feelings.
We can see from the graphs in Figures 4 and 5 that this tendency to be more positive manifests itself when comparing the likelihood to purchase a breakfast cereal. The Chinese, who are thought of as typically responding more favorably toward concepts, are the mostly likely to answer that they would purchase the cereal. The cereal market in China is actually positive, especially for cereals that are considered to be healthy. While cereal is not the most common item on the menu for breakfast, more Chinese people are looking for alternatives to the traditional Chinese breakfast.


Brazil also showed a favorable response to the cereal concept. In the numeric version, we see Brazilian and Chinese respondents switch positions, but both still were the most likely to purchase the cereal. Conversely, Japan, the U.K. and Italy were far less likely to consider the new cereal as different or to purchase it.
Different formations produce different results
Clearly, when it comes to Likert scales, there is no “one size fits all” approach. Different formations can produce different results - both within and across countries. In addition, different cultures have different response styles, even when faced with nominally identical scales.
Therefore, global researchers must carefully think through both how they ask questions and how they analyze results. There are many factors, both known and unknown, that influence findings around the globe. We would be comparing apples to oranges in many cases if we tried to build one perfect model that worked in all countries.
In all research, not just global research, it is critical to define and understand the target respondents and the cultures with which they identify. For the market research industry to uncover all the facts about scales and their effects on responses in every country and for every subject, we’ll need resources beyond what many have now. Until then, we need to be cognizant of all potential differences and adjust our global research designs to accommodate cultural variations - not just in language but in all aspects of lifestyles, attitudes, thought processes, social mores, behaviors and responses tendencies.