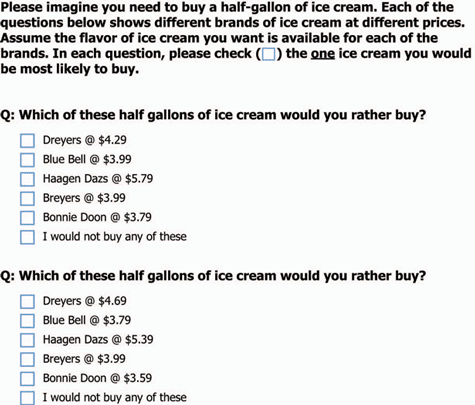
Editor’s note: Keith Chrzan is director of marketing sciences, Maritz Research, St. Louis.
Marketers take obvious risks when pricing new products or services, or changing the prices of existing ones. Setting price too high or too low will result in lower profits. In arriving at a pricing strategy, firms should consider several factors including: the strategic objectives; the product’s fixed and variable costs; the target audience; product positioning; distribution strategy; the competition; the product life cycle.
Pricing decisions typically involve analysis of historical data, competitive benchmarking and a healthy dose of managerial judgment. They should also involve research among buyers, because understanding price elasticity (the sensitivity of demand to price) allows more informed decision-making.
Researchers have several ways to do pricing research, all of them imperfect. People spend dollars in surveys more liberally than they spend them in the real world (in the survey world, your wallet is always full and your credit card is never near its limit). Nonetheless, some pricing methods work better than others and a designed experiment (a discrete choice experiment) often works best. In this article we also review several other approaches to pricing research and discuss relative strengths and weaknesses.
Designed pricing experiments
Designed choice experiments are appropriate for pricing research when:
- the price of the product can realistically be changed;
- there are competing products in the market, and;
- competitors may change their prices as a competitive response.
The questions that comprise a pricing experiment questionnaire are complicated and require paper-and-pencil or Web-based data collection.
Pricing studies usually involve a random sample of qualified purchasers in the product category, with typical sample sizes of 200-400 per separately reportable group. Variables affecting sample size include:
- number of brands in the competitive set;
- number of price points;
- expected complexity of the price sensitivity function;
- types of “special effects” built into the model, and;
- others.
The guts of a pricing study are several (usually 15-20) questions wherein respondents select from choice sets containing the client’s product(s), other products in the client’s portfolio and competitors’ products, each at different price points. In addition to brand names and prices, the products may also have specific attributes listed.
The first couple of questions from an experiment that has just price and brand in it might look as shown in Figure 1.

Across the several questions, the exact mix of brands and prices varies from one choice question to the next according to an experimental design. A design controls how brands and prices appear together and prevents them from being correlated. The benefit of using an experimental design is that the separate effects of brand and price can be extracted and quantified during statistical analysis.
There is a poor man’s version of this type of design called brand price trade off (BPTO for short). Rather than using an experimental design, questions are asked in an obvious and particular order so that it is painfully evident a pricing study is being conducted. Game-playing on the part of respondents frequently occurs, and valid measures of price sensitivity do not.
Questions for a multi-attribute experiment (one with price, brand and several other attributes) might look as shown in Figure 2.

As in the previous example, the exact mix of attributes and prices varies from one choice question to the next according to an experimental design. The design allows statistical analysis to quantify the separate effects of brands, prices, other attributes and even unique price curves per brand.
Price sensitivity curve
A basic output of a pricing study is a price sensitivity curve (Figure 3). It shows what preference share the model predicts a product will have at any given price point (at least any price point within the range tested).

A price sensitivity chart is static, assuming that prices of other brands remain constant. Competitors’ prices can and do change, however, so for a more dynamic result we build a decision support system (DSS) or “simulator.” Each of the effects the model quantifies can be built into an Excel-based simulator - a user-friendly interface enabling marketers to interact with the complex statistical model. Clients can then play their own what-if games with the effects that result from the analysis.
Not all decision support systems are created equal. While off-the-shelf simulator software sometimes suffices, custom-designed simulators tailored to specific studies usually do a better job of bringing complex models to life.
Realistic complexity
Pricing models can include a variety of kinds of attributes and effects. Standard off-the-shelf analysis programs that require forcing all clients’ problems into a single format that fits the specific software may be adequate on occasion. More often, clients’ markets are complex enough to warrant a custom design tailored to their particular situations. Real markets are complex, and they are complex in different ways. A best practice involves customizing the design of each experiment to the realities of the client’s market.
Some of the realistic design and modeling complexities which custom designs can accommodate are:
- Models incorporating heterogeneity. Because respondents differ from one another, simple models that merely average across all respondents distort and disguise the interesting and managerially informative diversity of respondents. When we recognize and model this diversity, each respondent has a separate model and a unique responsiveness to changes in price. This more realistic approach avoids assuming that everyone behaves like the average respondent and in this way it makes for more accurate modeling, and for the possibility of price-sensitivity-based segmentation.
- Models incorporating “cutoffs.” Introduced in the late 1990s, these models work very well. The idea here is that we often go to the store with an idea of what is a fair price for the item we’re shopping for, and what is the most we will pay for it. Many pricing studies simply ignore this reality. Others take it into account, but assume that a respondent will NEVER buy something priced above what she claims is the most she is willing to spend (in effect, they attach an infinite penalty to prices above the stated highest price a respondent says she is willing to pay). But we’ve all gone to the store and paid more than we’d intended for something, either because our selection was limited, or because it had some new features or benefits that made us willing to spend more than we had planned. A cutoff model quantifies finite penalties for prices over the stated maximum - there is a psychological penalty we pay for going over our planned budget, but the penalty is finite and is sometimes something we’re willing to pay.
- Models with “brand-specific” effects. Silly as it sounds, most pricing studies assume that price sensitivity is the same for all brands. It is better practice to design and analyze studies without assuming such uniformity of price sensitivity curves. Such models do not even require that all brands have the same price range (a requirement of the many widely used models). Good price sensitivity modeling does not impose preconceived notions of price sensitivity - it lets the data tell the story.
Price sensitivity meter
Sometimes a product is new to the world. Perhaps it is the start of a new product/service category. Or perhaps it has no direct competitors or even products that could be used as reasonable substitutes. In this case one approach is the price sensitivity meter (PSM), also called the Van Westendorp model after its inventor. After exposing the respondent to a concept description, we ask PSM’s four direct pricing questions about the new product:
- What price is so low they would question its quality?
- What is the highest price at which the product would still be a bargain?
- What is the price at which the product is starting to get expensive?
- What is the price at which the product becomes too expensive to consider buying?
These questions have face validity. They are the kind of thing a marketer would like to know about a product. In addition, they make a nice-looking visual. Variations on the cumulative distributions of the four questions are shown on a single line chart, like Figure 4.

Van Westendorp suggested that the intersections of these lines had special meaning. The rightmost one he called the “point of marginal expensiveness,” and the leftmost one he called “the point of marginal cheapness.” He posits the two interior points - “the ideal price point” and “the optimal price point” - as endpoints of a reasonable range to consider for pricing the product.
Despite its face validity, PSM has no strong theoretical foundation, and no track record of predictive success. It does not provide a way to optimize revenue, profits or net present value. Its complete reliance on direct answers to questions with obvious intent makes many researchers nervous.
However, PSM is easy to do: all it takes is four questions and Excel software. An exploratory pricing model like PSM may be the only way to go when we have a revolutionary or unique product to consider. When a product has competition, however, it requires the kind of realistic, dynamic pricing experiment described above.
Purchase intention surveys
Some pricing situations are not competitively complicated - the firm can change a product’s price without worrying about price responses by competitors. In this situation, two approaches come from the practice of concept testing.
In a monadic pricing concept test, there are as many cells of respondents as there are price points to test. Each cell sees the same concept, but members of the different cells see the concept at different prices. For reasons of statistical power, cells should contain at least 200 respondents. To reduce the impact of sampling bias, we may employ quota control measures to make sure we get the same mix of respondents in each cell. We also advise that prices be about 10 percent apart, or much larger sample sizes will be needed to read differences. Analysis consists of weighting the purchase intent measures and constructing a line chart, showing weighted purchase intent (Y-axis) as a function of price (X-axis).
In an effort to use less sample, some researchers use sequential pricing concept tests for price sensitivity modeling. This is simply a bad practice. In a sequential design, each respondent sees the concept and then rates his purchase intent at each of several prices. Even the dimmest respondent realizes this is a price sensitivity study, which pretty much ruins it. Moreover, we get very strong differences depending on whether we ask the prices in increasing or decreasing order (due to “ceiling” and “floor” effects).
Realistic situation
Marketers need to understand the sensitivity of demand to price. Market dynamics make pricing studies necessary more or less often, but companies probably do less pricing research than they should.
A designed choice experiment usually addresses our clients’ pricing needs best. This approach puts the respondent in a realistic situation where he can trade-off the various features of a product/service versus price, and it provides valuable information on all of the variables tested. When conducting pricing experiments, it is best to avoid off-the-shelf software packages for design and simulation. Most often these are not flexible enough to accommodate the complexities of real markets and may produce misleading results.
Although designed choice experiments are the current gold standard in pricing research, not all situations lend themselves to this approach. Another kind of pricing research might be more appropriate, such as the widely used price sensitivity meter, or a simple purchase intent study (monadic design). The former is applicable to new-to-the-world products; the latter may be good enough in competitively uncomplicated markets.