Automating market segmentation
Editor's note: Barry de Ville is a founder of FirstMark Technologies Ltd., Ottawa, Ontario.
Market Facts of Canada Limited is like any other business in the intensely competitive 1990s: its number one priority is not just to hang onto its customer base but to develop it as well. This means continuously looking for ways to increase its productivity and the value it delivers to its customers. This has led the company to explore the promise of relatively new PC-based software for data analysis and market segmentation - classification trees 1.
Classification tree software scans through survey-type data sets to automatically identify the key multi-dimensional attributes that define a customer segment. These products are highly interactive, and, as Market Facts has found out, highly productive 2. Hierarchies of customer groupings are displayed, in summary form, as classification trees. These trees provide a graphic summary of the results that is rapidly understood and easily communicated to non-statisticians.
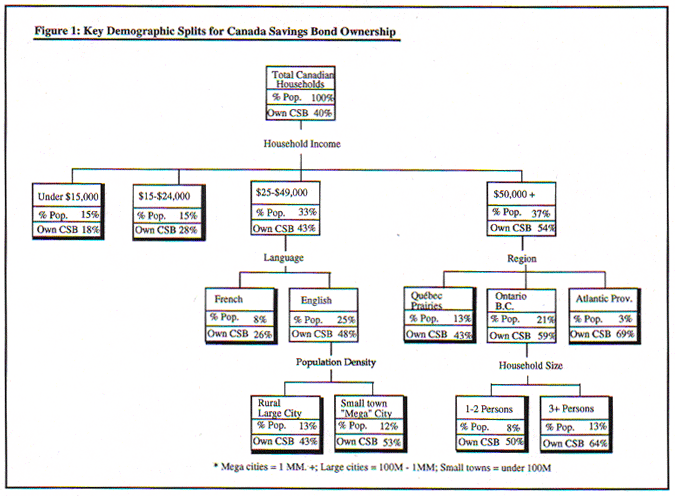
Figure 1 displays results that were produced by Dr. John Liefeld from the Dept. of Consumer Studies at the University of Guelph while on special assignment to Market Facts of Toronto. He performed a market segmentation analysis on the Market Facts' Household Flow of Funds survey. He was specifically interested in comparing classification tree methods and traditional market segmentation approaches based on crosstabulations.
He first extracted the relevant fields of information that could be used to characterize a market segment, starting with ownership of Canada Savings Bonds (CSBs), Retirement Savings Plans (RSPs) and Master Card ownerships. He selected CSB ownership to serve as the dependent variable in the analysis. As independent variables, used to form the characteristics of the market segments, he chose the following: household income, region of residence, population density, type of dwelling, ownership of residence, number of people in the household, language, gender, marital status, age, education, occupation, and membership in one of thirteen specially-constructed lifestyle segments (these are proprietary data constructs used by Market Facts to profile consumer habits).
Using the SAS statistical package to conduct a traditional crosstabulation analysis, Liefeld found that all thirteen independent variables were statistically significant. "The segmentation analyst's quandary is that this analysis is not parsimonious," Liefeld says. "It suggests that all independent variables are important in determining segment membership. It does not reveal which independent variables are more important or meaningful than others. It does not reveal which combinations of socio-demographic characteristics combine to define different segments of ownership of CSBs."
A parsimonious analysis
To answer the knotty questions about variable importance and variable combinations, Liefeld turned to classification tree methods. "A (classification tree) segmentation analysis whittled down CSB ownership to five variables. It revealed that household income is the most powerful predictor of who was likely to own a CSB: ownership is highest when household income is $50,000 or more (54% here owned CSBs) and is least for those with household income under $25,000. When household income is greater than $50,000 the second best predictor variable is Region. For household income less than $50,000, language (English or French) is the second best predictor variable," Liefeld says.
These results are illustrated in Figure 1. It shows how Canada Savings Bond ownership varies primarily as a function of Household Income. Notice how the first branch of the classification tree shows the optimal clustering of income values to form the branches of the tree. This clustering is performed automatically using statistical measures of association (either X2 in the case of a categorical dependent variable - as shown here - or the F-test in the case of a continuous dependent variable 3). The clustering has the effect of forming groups of codes which are as alike as possible yet which are as maximally distinguished from the other groups of codes, or nodes, at the same level of the classification tree.
The automatic grouping of codes on the branches of the classification tree is one of the most important benefits of these software packages. Not only does the software save time in looking through many relationships - and collapsing similar values together automatically - but, Liefeld says, the results are "more informative, parsimonious and reliable than those arrived at using bivariate crosstabulation analysis."
Multi-way hierarchies
Classification trees go beyond bivariate relationships, however: as can be seen in Figure 1, they produce multi-way hierarchical relationships. At each stage in growing the tree the analyst has the opportunity of interactively picking the best split variable. In this example Liefeld chose income. Once this is done the software descends to the next node and applies the tree growing process again. This gives rise to the inverted tree structure that characterizes this technique.

The final result is a classification tree that contains multi-dimensional effects - including combinations of variable interactions - but which are displayed as a tree rather than as a vector of coefficients, for example, as is usually the case with traditional multiple dimension techniques. Each branch on the classification tree can be interpreted as a series of nested tables.
Gains charts
In many cases the analysis could stop there: each of the bottom nodes of the classification tree are taken to form a unique market segment, each one deserving (or requiring) special treatment in sales, marketing and advertising campaigns. However, as Peter Greensmith, senior vice president of research and marketing at Market Facts, says, "generally speaking, when segmenting markets...it is not only important to isolate the significant variable splits but also to make a judgement on the level of segmentation detail that has practical utility. For example, segments representing only a small percentage of the total market may not have practical value." Greensmith has found that a gains chart, illustrated in Figure 2, is well-received by clients in order to assess the potential value of each segment in developing their market plans.
The chart displayed in Figure 2 shows that while nine key segments have been identified as nodes on the classification tree, three segments (shown at the bottom of the chart) account for almost half of the CSB owners. By identifying segments in this fashion Market Facts is in a position to advise its clients where they can best invest their marketing dollars. In Figure 2 the best segments are those with the highest gains ratios; for example, the segment at the bottom of the chart - people who earn at least $50,000 per year and who live in Ontario and British Columbia in households of three or more persons - represent 13% of the total population but account for 20% or one-fifth of the total CSB buyers. This gives them a gains ratio of 1.5 - a leverage of 50%!
Benefits of classification trees
The primary benefits of classification trees are the thorough, automated analysis and time savings they offer. As shown above, crosstabulation approaches do not readily summarize data relationships - certainly not when it comes to producing three-way and higher dimensional tables. There are just too many operations to perform and tables to look at. In the case of CSB ownership, presented in Figure 1, there are approximately 225 different ways (over 25 million) that the predictor codes could be clustered with respect to their inter- and intra-group values on the Canada Bond Ownership variable - a daunting search task if done using traditional statistical methods. Classification trees do this job automatically - usually in a matter of minutes.
Another benefit of classification trees is the ability to calculate all possible segmenting variables at any level of the tree. This provides the user with the ability to preview all possible classifier variables at any stage in the growth of the tree in order to pick the "best" classifier (from the point of view of explanatory power, theoretical market model, or both).
Once a branch is grown and descendent nodes (or leaves) of the classification tree are displayed the process of segmenting lower nodes can begin anew. Thus, in descending to lower and lower nodes the full tree is grown. This produces a refined market segmentation model where the bottom nodes, or branches, are presented as unique market segments. By tracing the branches that define these terminal nodes the multi-dimensional attributes that define the market segment may be identified. This simplicity of presentation is a major benefit in its own right: each market segment is clearly identified as a separate node of the classification tree. Since groups of codes are clustered together the information is presented in summary form. So the information is highly summarized and rapidly digested. And unlike most multi-dimensional techniques, the information is displayed graphically. So the results can be immediately duplicated and distributed to non-statistical audiences.
The kinds of classification tree software illustrated in the Market Facts case study have a long history in social research 4. But it is only recently with the advent of personal computer software packages that the benefits that these packages offer have become widely available. Classification trees will play an increasingly important role in the marketing activities of companies now and in the years to come because they enable suppliers of data and research products to quickly identify niche markets for products where the demand is strong and where the purchasing power is greatest.
Footnotes
1. Classification trees are PC-based implementations of mainframe AID, CHAID and CART packages.
See Steven Struhl's article "Classification tree methods: AID, CHAID and CART" in the February 1992 issue of Quirk's Marketing Research Review for a comparative analysis.
2. There are two PC products that are widely available in the market now - one is developed by SPSS Inc. of Chicago, Illinois (PC+/CHAID); the other by FirstMark Technologies Ltd. of Ottawa, Canada (KnowledgeSEEKER).
3. The type of dependent variable normally determines whether the analysis is considered CHAID or CART. CHAID refers to CHI-squared AID, so works with a categorical dependent variable, CART refers to Classification and Regression Trees, so works with a continuous dependent variable. KnowledgeSEEKER, referred to above, perform both kinds of analysis.
4. For a description of the early AID package see Morgan, Baker and Sonquist "Searching for Structure," Institute for Social Research, University of Michigan, Ann Arbor, Michigan, 1973.