Editor’s note: Jennifer Van de Meulebroecke is vice president at TRC Market Research, Fort Washington, Pa. Michele Sims is vice president/research management at TRC.
Benchmarking results against the competition has clear benefits, from simply understanding where you rank to understanding how the competition achieves the success they do. Yet a survey of researchers indicates that many view benchmarks with skepticism. Understanding how to evaluate benchmarks, and when to question your results, is critical to making informed strategic and tactical decisions.
Why benchmark? As marketing researchers designing and undertaking custom quantitative projects, clients increasingly need to provide external context for their research results, particularly against benchmarking or normative data. For some industries, these comparisons are made easy by industry surveys such as CAHPS (Consumer Assessment of Healthcare Providers and Systems), syndicated data sources or published survey results. Yet not all industries have such surveys, and in many cases existing benchmark data are not easily compared to a custom survey.
Our firm, TRC, sought to understand how researchers view benchmarking in an effort to provide some guidance on how to use it. We reached out via an online survey to 97 research buyers and users in the spring of 2009.
First, some background: all 97 are involved in market research at their organization; 83 have a designated market research function. They represent various industries but have the highest concentrations in insurance, utilities, high-tech, health care and financial services.
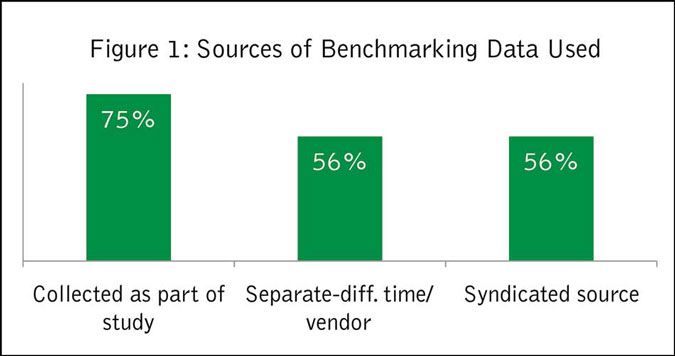
Nearly all have used benchmarking data in their current job. Most collected this data as part of a study they were conducting, for example, gathering competitive ratings alongside customer ratings in a satisfaction survey. Syndicated data or collecting data at a different point in time/through another vendor were also used by a majority (Figure 1).
How are researchers using this data? Over half (51) mentioned using it to provide context or comparative data against which to measure their own results. As one researcher put it, “Is 60 percent sat good? If other companies are at a 40 percent level, then absolutely. However, if the others are at 90 percent, not so much.”
Twenty said they use the data to help set strategic goals, allocate resources or establish performance targets. Sixteen mention tracking changes or trends over time. There were several mentions of monitoring awareness (advertising, brand) and market forecasting as well. Three researchers admitted they are benchmarking primarily because management or internal stakeholders demand it. With the stakes so high, are researchers sure they’re getting what they need?
We then asked researchers to focus specifically on benchmarking data collected outside the primary study (what we’ll call external benchmarking data). We asked them to rate both their understanding of how external benchmarking data are collected, managed and reported and their confidence in making comparisons to this type of data. We found something unexpected: The longer they’ve been in research, the less trust researchers have making comparisons to external benchmarking data (Figure 2).
Yet understanding of benchmarking data does increase with tenure in the business. We would expect confidence to increase with understanding, but instead we become more critical - or more cynical.
So does that mean you shouldn’t trust external data sources? Of course not. But it does mean you should approach their use with caution.
What should you be mindful of in making benchmarking comparisons? According to our surveyed researchers, the foremost of these is questionnaire consistency (see Figure 3).
Having consistent scales or answer categories is the most important consideration regardless of tenure. Question wording is also critical to maintain comparability.
Data collection methodology is also highly relevant. Ensuring the same methodology is used (Web vs. phone, for example) was important to two-thirds of researchers. Field period - or making sure the timing overlaps - was less critical.
Great value
To the extent that these items are consistent between your data and the external data, there is no question that making these comparisons is of great value. But what are the ramifications if these items don’t align?
Question text, scale and response category differences can be difficult to overcome. We’ve had a lot of experience converting data collected with one scale to match a new scale. Making those comparisons becomes even trickier in combination with other differences such as question wording or data collection timing.
Also bear in mind how missing data (don’t know, not applicable, refused) are handled in both studies - scale conversion won’t overcome a fundamental difference in the way the data are reported.
Whenever possible, learn how your normative data are collected before you do your own data collection. This way you can match the question wording and scales to the normative data. Barring that, designate a subgroup of sample to administer the key questions to match the syndicated data.
If the screening or sampling criteria are different, there isn’t a lot you can do to overcome those differences. But there are a few options to bring value:
The most important thing to do is to recognize whether differences exist. If you are comparing your product’s buyers to buyers of the category in general, ask questions about how those buyers were screened: Recent buyers - how recent? First purchase or repeat only? Adult-only or adult and teen? U.S.-only or international? Understand the universe to make informed decisions.
Next, consider filtering your own data to match that of the benchmarking data. Suppose you want to compare consumers in your footprint to normative data but the normative data was only collected in a sub-region of your footprint. Filter your own data to match. You won’t get a total market view, but you will have comparative data for specific regions.
Similarly, if the provider of the benchmarking data can cut their data in different ways, you may be able to filter their data to match your own.
Finally, other methodological disparities, such as field period timing, data collection methodology or sponsorship identification, also impact comparability of data sets. Our experience tells us that changing from non-identified to identified sponsor not only can increase survey response rate but also have a positive impact on the ratings. Competitive ratings collected with a blind or neutral sponsor can suffer in comparison. And asking competitor ratings only among your own customers can lead to a skewed view of the competitive landscape.
Analytic eye
So what’s the bottom line? Dig into the methodology of the benchmarking data, and as much as you can, keep an analytic eye for discrepancies that can mar your comparisons.