Editor’s note: Raymond Raud is chief engineer of Smart Software Company. Michael A. Fallig is vice president of Audits & Surveys. The authors are particularly grateful to Joel Dorfman of Audits & Surveys for introducing R. Raud to the problems of open-ended coding and continuing patronage of the project, to the colleagues in Smart Software Company for their help in preparing the article, to Irv Roshwalb for his numerous suggestions of improvement, to Robert Ruppe and his team in C.T.I.S. for patience and diligent work in testing the program.
Abstract
The cost and accuracy disadvantages of manually coding open-end questions can be overcome by the application of computer algorithms based on neural networks, an aspect of artificial intelligence which simulates the human brain’s ability to learn. This article describes such a program and a field test’s results.
For nearly 50 years researchers having been debating the advantages and disadvantages of eliciting survey responses with open versus closed-end questions (e.g., Blair, Sudman, Bradburn, Stocking 1977; Bradburn 1983; Bradburn, Sudman, and Associates 1979; Dohrenwend 1965; Dohrenwend Richardson 1963; Lazarsfeld 1944; Schuman, Presser 1981; Sheatsley 1983; Sudman Bradburn 1982). Perhaps because the body of research suggests that one form of question is not clearly superior to the other in every situation, most investigators conclude that both forms have their place in survey research.
Findings from their nationwide field experiment led Blair, Sudman, Bradburn, and Stocking (1977) to conclude that open questions reduce the amount of under reporting of the frequency respondents reported engaging in threatening or socially sensitive behaviors (e.g., alcohol consumption, drug use, masturbation, sexual intercourse). But as Bradburn (1983) and Bradburn, Sudman, and Associates (1979) note, question form (i.e., open versus closed-end) did not appear to affect reports of whether or not the respondents actually ever engaged-in the behaviors which were measured.
Sheatsley (1983) has argued that closed-end questions have several other disadvantages when compared to open questions: They suggest answers that respondents may not have thought of before; they force respondents into what may be an unnatural frame of reference; and they do not permit them to express the exact shade of their meaning (p. 207).
But, in part, because of the time and expense involved with using current methods to code open questions, both Sudman and Bradburn (1982) and Sheatsley (1983) suggest that open end questions be limited to the following situations:
(a) when there are too many categories to be listed or foreseen;
(b) when one wants the respondent’s spontaneous, uninfluenced reply;
(c) to build rapport during the interview, following a long series of closed questions that may make respondents feel they have no chance to express themselves;
(d) in exploratory interviewing and pretesting, when the researcher wants to get some idea of the parameters of an issue, with the view to closing up the questions later. (Sheatsley, 1983, p. 208).
According to Schuman and Presser (1981) the common feeling has been that "open questions avoid the possibility of a response-order effect" (p. 61) while such a possibility exists with closed-questions. However, after conducting a series of field experiments using open and closed forms of the same questions they could find no evidence to support this claim for the variables they measured. Nor could the investigators find any clear evidence that open questions in general were superior to the closed-end form (Schuman & Presser, 1981, Chapter 3).
It is important to note that while Schuman and Presser could find no differences supporting the superiority of open questions, in the course of their investigations, they indeed found significant univariate differences between the responses obtained by asking questions in an open versus parallel closed fashion. More important, in the course of conducting their experiments and devising their survey instruments, they confirmed, by serendipity, one of the more important reasons for using the open form of a question: "closed questions constructed in an a priori way may fail to provide an appropriate set of alternatives meaningful in substance or wording to respondents" (p. 80). Just prior to fielding parallel forms of a question about the most important problems facing the U.S. today, parts of the country had been hit with an unusually cold and hard winter. The media, at the time, according to Schuman and Presser, gave heavy coverage to some of the debilitating effects of the weather.
Although the closed form of their question had been developed from open end responses (generated by respondents sampled at some earlier period of time), it did not provide closed categories about weather-related issues. According to Schuman and Presser, inspection of the answers to their February 1977 questionnaire fielding revealed why it is important to make certain, before closing a question, that the closed form has appropriate answer categories. Their finding also seems to argue for when it might be key to use an open form of a question.
About 22 percent of the respondents exposed to the open form of the question during their February 1977 experiment were coded into a "food and energy shortages" code. And although the closed form provided an "other specify" category, most respondents exposed to this form selected answers from among those provided on the closed-end list--which had not included a "food and energy" code. Note that this experiment also reveals that providing an "other specify" category to an otherwise closed form of a question does not replace asking the question in its open form. Their own research, supported by findings of Belson and Duncan (1962), led Schuman and Presser to conclude:
"There is probably no adequate way to obtain a full array of responses by combining closed and open methods in a single question, because the very provision of closed alternatives discourages spontaneous responses that do not fit the listed alternatives." (p. 87)
Before continuing, it should be noted that researchers do not entirely agree on the precise definitions of open and closed questions. The general consensus is that the definition of open questions goes beyond the simple notion that these are questions "answered in the respondent’s own words" (Sudman & Bradburn, 1982). A key aspect of open questions is that the interviewer records, verbatim, in respondents’ own words, the answer to the question (c. Sudman & Bradburn, 1982). In essence, for open questions, all that is provided to the interviewer is "white space" (or the computer equivalent) on which the answer is to be recorded. Then, generally after field work is completed, coders review the open end questions, "write-off" responses on to index cards or the like, sort the responses into broader categories which encompass a set of verbatims and develop a set of categories in which the verbatim answers eventually are coded. More will be said about this later.
A form of question that many may argue is an open question is the "field" coded question, which Sudman and Bradburn (1982) and others have argued is really a closed question. The question itself may be asked just like an open question, "what is your occupation," that is, without giving respondents a set of alternatives to choose from - but instead of providing "white space" it provides a list of categories not revealed to the respondent, from which the interviewer is to "on-line" code the response generated by the respondent. Many researchers, Sudman and Bradburn (1982) included (also see Sheatsley, 1983, p. 208), argue that "field" coded questions should be avoided whenever possible because there is a host of inherent problems associated with using interviewers as coders. As Sudman and Bradburn (1982) note, "the pressure of the interview situation makes it likely that greater coder error will be introduced in a field-coding situation than in office coding." (p. 153)
But office coding as it is traditionally done today in commercial research firms has potential drawbacks as well. It can be a time-consuming, labor-intensive, expensive operation developing codes, coding responses into categories, and maintaining a professional coding department. Furthermore, as coding is accomplished today, there is the potential of reliability problems--particularly with tracking studies in which different waves of the study have been field coded at considerably different periods of time.
While office coding of open-end responses has been looked on as an expensive operation, the advent of relatively cheap computer power and with advances in an aspect of artificial intelligence known as neural networks, newer and considerably less expensive methods for coding responses have recently been developed. The remainder of this article describes this new form of coding and a series of tests which were conducted to examine the response codes developed using this new method.
Using neural networks for coding
Abstraction and learning are typical features of human brain. Corresponding algorithms are required for an open-ended questions coding program. Artificial intelligence, a recent direction in computer engineering, derives its algorithms from the simulation of functioning of human brain. Expert systems (an artificial intelligence approach) rely on the pragmatic relationships between events and objects in the application area. These relationships are usually expressed in the form of rules, hence the other name: rule-based systems. The rules represent the practical knowledge of experts in the field. Expert systems have found extensive applications in various areas combining the "common sense" of experts with the conventional mathematical models and data processing algorithms (for example, Keon 1991). The major effort in building an expert system goes into capturing and organizing the expert’s knowledge. In many cases the knowledge is on a deep intuitive level and difficult to formulate in precise terms. This complicates the task even further. An earlier project to automate the coding process with computers has been reported by Pratt, Mays (1989). Expert systems technology was partially used in this project.
Neural network, another strategy of artificial intelligence, simulates the human brain’s ability to learn and draw abstractions from the data. Thus, neural network does not require the participation of a domain expert in the learning process. The technology is applicable also in areas without experts or where only intuitive knowledge is available. A typical application for a neural network is pattern recognition. Optical character recognition is a perfect example. Starting from some level of education, we all know how different characters look. We are often able to recognize them relatively fast even from very obscure handwriting. Yet, we cannot explain how we do that. Neural networks are trained to recognize the characters using the graphical representation of the text. Once trained, the network is able to recognize a similar font or handwriting quickly.
Open ended question coding is similar to pattern recognition. First, the coder records the word patterns and abstracts the repetitive concepts (ideas) they express. Then he or she applies this knowledge to the classification of responses. This similarity led to the idea of building a neural network for open ended question coding.
The search for an efficient learning algorithm for word patterns and the results of this effort are described below in the form of a case study. The feasibility of neural network technology for the open-ended coding is the topic of discussion.
Learning in neural networks
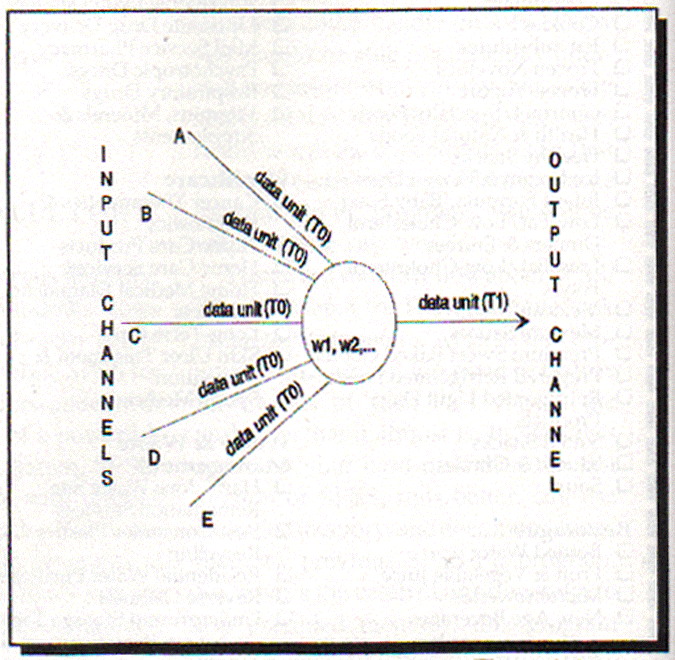
Before getting into the details of the learning algorithms, let’s review briefly the general terminology of neural networks. A neural network consists of equal basic processing units - neurons. All neurons of a network operate in parallel. They process the data in units meaningful for the application. Being equal it also takes them the same time to process the same amount of data - a processing cycle. The neurons are connected to the outside world and to each other by data channels. Each channel carries one data unit for each processing cycle. A neuron has many input channels and a single output channel. The neuron calculates its reaction to the data units in its input channels and forwards it into the output channel in one processing cycle. The internal state of the neuron is defined with the values of its state variables. They are involved in the calculation of output. The neuron on figure 1 at the moment T0 has data in its input channels A, B, C, D and E and it puts out the reaction at T1 - a processing cycle later.
The neurons in the network are organized in layers. A neural network also has its input and output channels. The neurons fed directly from the input channels of the network are called the input layer. The neurons feeding the output channels of the network are called the output layer. The layers between the input and output layers are not directly visible from the inputs or outputs of the network. They are called hidden layers. The data from each input channel of the network is fanned out into the input channels of the network’s input layer. See figure 2 for an example. The output channels, in turn, are fanned out into the input channels of the next layer. The number of layers of the network is theoretically unlimited. In practical applications, up to three layers are used. The processing in the network occurs in parallel. For the network in figure 2 it takes one processing cycle for the input layer to calculate its reactions and another for the next layer to get the network’s reactions out. Although the data units in the input of all neurons of a layer are the same their reactions will vary because the internal variable’s values are different. The state variables of all the neurons in the network constitute the memory of the network.
There are two phases in the data processing with a neural network. First, the learning (or training) phase, in which the network is processing data and at the same time the neurons are adjusting their reactions so that certain combinations of data units in the input (data patterns) will induce certain reactions in the output of the network. Learning occurs by changing the network’s memory - internal variables of the neurons. Second, the data processing phase, in which the network’s memory remains stable. Consequently, the same reactions will appear in the output of the network in response to the same data patterns in the input.
Neural network technology incorporates several different ways to simulate the human learning process. New algorithms are announced weekly. A full explanation of all variations is outside the scope of this article. A popular overview of some variations can be found in Caudill, 1990. We will analyze two main approaches to the learning process from the aspect of applicability to the open ended question coding. Those are: learning from the examples and learning from the data.
For further discussion, we need to associate some terms of neural networks with the terms of the coding process. The answer text serves as input to the neural network. It consists of words, which are the individual data units. The reaction of the network is a code corresponding to the particular text in the input of the network. The learning phase of our neural network corresponds to the development of the code list. The neural network’s data processing is the actual coding of the answers.
Learning from examples
The first approach, learning from the examples, is one of the most developed classes of learning algorithms. The training set (the examples) contains the input as well as correct reactions to the input -the output. The learning process starts with a randomly initiated memory of the neural network providing randomly correct reactions to the input. As in the human learning process, correct "guesses" are rewarded and the incorrect ones "penalized." The best known back propagation type of learning means modification of the neuron’s memory according to the expected reaction to the input. In other words, the knowledge about the correctness of the output is propagated back through the network layer by layer, starting from the output layer. Each neuron will modify its memory according to the feedback given to accommodate expected reaction to the known input from the source data.
The method assumes that the real data contains the same (or similar) combinations of input data. Obviously, the speed and quality of learning depend heavily on the volume and composition of the training set. The method works well for applications where such sets can be compiled with a reasonable effort. It assumes also that the distribution of various input patterns is stable and predictable.
Good application examples are the character recognition programs where the set of possible input is relatively stable and predictable. The construction of the training set is straightforward also. To be useful for open ended question coding, a representative subset of answers should be coded manually first. That subset would serve as the training sample for the rest of the coding process. Effectiveness of learning and quality of coding would depend on the composition of the training sample. The automated process would include: representative training sample selection and manual coding of the selected sample. The training sample selection for our application is complicated: the sample has to include word patterns with low number of occurrence, the unique ideas, and the common ideas expressed with unique words.
Learning from the data
The second approach suggests un-supervised learning from the data. The corresponding networks are called self-organizing or Kohonen-type networks after the name of the first researcher in that domain. The method is based on the idea that similar input data patterns are saved in the memory of neurons through repetitive occurrence and thus cause the same reactions. A similar process is probably going on in the newborn child’s brain while he or she is learning to distinguish the surrounding objects. Note that the child is able to recognize the objects much earlier than he or she learns their names in the language.
Correspondingly, exact reaction (its value) of a neural network to an input data pattern can not be pre-determined. Matching and similar patterns, if they occur frequently, are saved in the network’s memory. They are recognized next time in the input and the network returns the same output. The reactions to the different input patterns are different too. That reaction (output) will thus identify the input.
Here’s how the self-organizing network operates and learns. A neuron saves in its internal memory a data pattern it considers its "own." In each processing cycle the neuron determines the "similarity" of the pattern in its input to its "own" pattern. The "similarity" is a value proportional to the distance between its "own" pattern and the input pattern. The network arbiter collects the "similarity" values from the neurons and determines the most similar neuron - the winner. The winner has the privilege of learning and generating the network’s output. Learning in general terms means adjusting its "own" pattern so, that the "similarity" with the current input pattern increases.
Since the same input data is used for learning, the training set selection problem does not exist. In addition, the distinction between learning and processing phases becomes fuzzy. While calculating its reactions to the input data the network is also continuously learning from it. Thus, the learning speed depends on the composition of the input data and on the desired quality of processing. The algorithm is statistical in nature. Therefore, patterns with a low number of occurrences may not create sufficient trace in the network’s memory to be distinguishable.
Our learning approach
Learning from data is appealing due to its practical characteristics - a fully automatic training process without the need for the complicated training sample selection and manual coding phases. The self-organizing network works in open ended coding as follows. First, the network scans the text of answers and saves the repetitive word patterns in its memory. It saves the patterns so that groups of answers with similar word patterns are recognized by distinct output values-codes. Besides learning, the network codes the answers in parallel. The learning phase can be interrupted as soon as the desired coding quality level is reached. Learning speed depends on the number of different word patterns (codes in the code list) one would like to count, the frequency of those patterns in the text, desired quality of coding.
The algorithm works well for the patterns that appear frequently in the text. Conversely, the network has trouble coding responses with unique ideas and also with the answers where common ideas are expressed in unique word patterns. Unique ideas can be ignored as statistically meaningless. Unique word patterns with common ideas are typical for open-ended studies. Therefore, a solution has to be found for them.
The program
The features of the program with the self-organizing learning algorithm tailored to the open ended questions coding are described in this section. The first challenge is building a meaningful bridge between the terms of the application and the terms of the technology. An effective and practically useful algorithm for the goal, we studied the characteristics of the data. The results provide for an efficient algorithm with a self-organizing neural network in the core of automatic code list generation and coding operations.
Building the algorithm
Identification of data units in the input channels of the neuron and the neuron’s data processing algorithm are the key issues of the algorithm. To find the efficient assignment of data units we experimented with a simple scheme on many open ended answer files. Each word was treated as an autonomous entity discarding the semantic structure of the sentence. Analysis of results showed that the coding error due to this simplification was generally below one percent and never exceeded 1.5 percent. We decided to ignore the semantic structure of the sentence for the first version of the program.
A simple scheme follows from this decision. All different words from all answers of a file of answers make up the dictionary. Each word of the dictionary represents a particular in the inputs of the neural network. The value of this word in an answer is "true" if the word is present and "false" otherwise. A closer look at the mix of words shows the following: majority of the words are present in the text only once, thus useless for coding, prepositions, pronouns, substantives, articles - functional words, are also useless for coding, there are a number of misspelled variations of the same word in the text and there is no simple way to recognize them automatically, a set of words are aliases, thus only one could represent the group, a number of words can be considered aliases in the context of the particular open ended question.
A common set of functional words, aliases and even common misspellings can be compiled. Using this syntactic knowledge the program automatically eliminates the functional words, replaces the synonyms with one form and replaces the misspelled forms with correct ones. The operator’s help is required to identify the remaining misspelled words and, most important, the context dependent aliases.
The operator in the role of an expert is introducing new syntactic and semantic knowledge of the language as well as the application domain of the study. Automatic and human assisted operations on words are called dictionary operations. The words remaining in the dictionary after the dictionary operations are called the selector words. The algorithm uses only selector words as input for the neural network.
The network’s structure and operation for open ended coding is discussed next. Each neuron in the network has its unique identification number. The neuron’s internal memory contains a word pattern the neuron considers its "own." Our neural network has one hidden (processing) self-organizing layer. Each neuron gets all the network’s inputs. For each processing cycle the text of one answer is fed into the network. All neurons compare themselves to the input. The network returns the identification number of the most similar neuron - the winner. The similarity is defined as a ratio of matching words to the total number of words in the answer text. In order to increase the similarity in the learning phase, the winner adds words to its short term memory or replaces less useful ones. There are several other processes active concurrently as well. They simulate the human brain’s forgetting process as well as the anchoring of significant words in the neuron’s long-term memory. In technical terms they eliminate the insignificant word associations and manage neuron’s memory. During the learning process each neuron becomes the representative of a word pattern. The word patterns are the potential codes on the code sheet.
The coding process and neural network
Done with the general algorithm, we will discuss the coding process with the program and the role of the neural network. All tasks of a coding project: dictionary generation and manipulation, code list generation, code list editing and printing, coding of answers, coded file review and editing, are supported by the program.
First, the program builds the dictionary as a list of different words from the answer text. It flags the common non-selector words and joins common alias words before presenting the dictionary for review and editing by the operator. The dictionary appears in the form of two lists. Both the non-selector list and the selector list may contain sub-lists of aliases. The operator can move words from one list to another, join words to alias group sub-lists or break them out if required.
Code list generation normally follows the work with the dictionary. Least similar answers in the set are used to initialize the neural network for the code list generation. The program trains the network, processing all answers in the file once in each training run. It keeps track of the learning activity over the run calculating a training index. Stabilization of the index signals the end of the learning process. Finally, the program translates the network’s memory into a code list. Each code in the list is defined as a boolean expression of words associated with a code number. Semantically these are the words used to express a concept in a set of answers. The words of the code definition are joined with the boolean operations "and" and "or." The operator can review and edit the code list in this format. The operator can by-pass the code list generation if a previously developed code list should be used for coding. This is typically the case for continuing studies.
The neural network assigns codes to the word patterns, but coding of ideas and concepts is usually required. Abstraction of concepts from the word patterns by the operator is expected at this point. Besides the verbatim of the study, it depends also on the goal of the study, level of detail required and other aspects not explicitly present in the answers. Therefore, we opted for an interactive approach. The operator has to review the code list, identify the word patterns of the same concept and assign the same code number to those patterns.
Once the code list is finalized the coding is fully automatic. The program loads the network with edited code definitions from the list. A modified processing algorithm is loaded into the neurons as well. The new algorithm is evaluating the boolean expression of the corresponding code in addition to the quantitative "closeness" measure calculated by the earlier algorithm. For processing, the program reads the answers and each neuron calculates its boolean value and the similarity. The coding operation is supported in two modes: Single code per response mode selects only the most similar code if several neurons return "true"; Multiple codes per response counts all neurons with the boolean value "true" as relevant.
Finally, the coded file is available for the review and editing by the operator. Here the operator can overwrite the codes assigned by the program if he so chooses. The program collects also some code distribution statistics. Those are the number of answers in the code group and maximum dissimilarity of the answers under the code.
In summary, the program uses a neural network for both key phases--code list development and coding. Although significant operations are automated by the program, full automation is not achieved. The automation of operations is summarized in table 1.
The field trial
In order to determine the potential impact of the automation to the open ended questions coding a set of field tests was conducted. The evaluation of following characteristics was set for the goal of the field study: autocoding quality and speed in comparison with manual coding; the influence of previous computer and coding skills; the significance of special training. 
The experiment
The answers to three questions were used for the field test. The first file was compiled from the answers to the question "Why did you choose ABC as your soft drink supplier?" (referred to below as file ABC). The second one asked the same question from XYZ customers (referred to as XYZ). The third file included the responses to the question "What were your primary reasons for selecting your supplier?" (referred to as BOTH). The code list developed for the first two questions was used for the third file.
Three people coded the files independently. Their experience, relevant to the test is summarized in table 2.
Table 3 compares the time spent on the code list development and coding of the test files. The data in the manual coding column includes 2.5 hours of code list development for each of the first two files. The productivity of coding increased from 1.3 up to 10 times on first two files of the test. Strong linear correlation with the experience of working with the program is noticeable.
The third file, "BOTH" represents a tracking study. Coder 1 was not asked to code the third file, but the productivity increase was significant (almost 10 times) for coders 2 and 3.
Detailed characteristics of automated coding
The code list development and coding results of the ABC file are covered in detail in this section. Table 4 summarizes the code labels produced by the participants and compares to the labels from the manual process. We boxed the groups that were labeled differently by the participants but were based on the same word patterns.
Table 5 shows the summary statistics of coding. Same code groups are boxed again for easier comparison. Due to the semi-automatic operations the differences in the results are from fractions of percentage points up to 4 percent. The variations of the results are in the same range between the participants of the test and the manual coder. Since the automatically generated code list is open for editing each coder introduces his personal view into the results. In our tests a subset of answers contained several ideas. The multicode mode of the program was not used in the tests. Therefore, the participants had to guide the program to choose the most important concept from the answer. Subjective priorities explain most of the differences among the test participants.
In general, the test participants seem to have difficulties in isolating relatively small groups (less than 2 percent from the total). All the test participants failed to isolate one significant group "Satisfies needs; no reason for change to another supplier" with 2.87 percent of responses. Later analysis did not reveal the cause of these phenomena. The algorithm positively isolated the word patterns even if they were present only in two responses. The participants chose to join it with other, similar word patterns. This could be due to the lack of previous training in open ended questions coding.
The consistency of code development is illustrated with figure 3. The codes boxed in table 4 (same concept, different labels) are combined for the charting purposes. The groups of codes with high correlation are on one end of the chart. The variation in the code development among them is in the order of single percentage points. Inconsistent code groups are on the other side of the chart. Some of the reasons for these variations were discussed earlier. Reasons for the differences between manual coding and automatic coding are addressed below.
Finally, the actual coding results. As mentioned earlier, the coding is practically instantaneous with the program. In addition, as we discovered in the tests, it is also more consistent with the code list. Thus, leading to higher quality results. To support this statement, we included some examples from the ABC file. Panel 1 shows a sample of consistently coded responses. Although the wordings of the code labels do not match exactly, the results line up nicely. Panel 2 lists some of the responses where the participants ended up with different codes than the manual coder. In some cases, all assigned codes are relevant, but different concepts were considered to be primary. In other cases the errors of manual coder are obvious.
Conclusions of the test
Although the test can not be considered conclusive, some of the practical aspects of the program are evident: favorable automated coding appears to be more consistent (higher quality) than manual coding. Automated coding is significantly faster. Training and experience in the use of the program significantly increases the productivity. Computer literacy is not a prerequisite. Neutral: Some errors are inevitable whichever method is used. Both methods are subjective in creating the code labels. Negative: It requires re-orientation of current coding staff.
Conclusions
Neural network technology is mature enough to be used in various complex applications thus far considered to be unapproachable for computers. Building the applications sometimes takes creativity and innovation, but it pays off with significant support to the intellectual performance of a human operator. Better results in the code list development can probably be expected from a multi-layer network and from an algorithm taking the consideration the semantical structure of the sentences.
References
Blair, E., S. Sudman, N. M. Bradburn and C. B. Stocking (1977), "How to Ask Questions About Drinking and Sex: Response Effects in Measuring Consumer Behavior," Journal of Marketing Research, 14.
Bradburn, N.M. (1983), "Response Effects," in Handbook of Survey Research, P.H. Rossi, J.D. Wright and A.B. Anderson , eds. New York: Academic Press.
Bradburn, N.M., S. Sudman (1982), Asking Questions. San Francisco: Jossey-Bass.
Bradburn,N.M., S. Sudman, and Associates (1979), Improving Interview Method and Questionnaire Design: Response Effects to Threatening Questions in Survey Research. San Francisco: Jossey-Bass.
Caudill, Maureen. (1990) "AI Expert. Neural Networks Primer," San Francisco: Miller Freeman Publications.
Dohrenwend, B.S. (1965), "Some Effects of Open and Closed Questions on Respondents’ Answers," Human Organization, 24, 175-184
Dohrenwend, B.S., S. A. Richardson (1963), "Directiveness and Non-directiveness in Research Interviewing: a Reformulation of the Problem," Psychological Bulletin, 60, 475-485.
Keon, John W. (1991) "Point of view: Understanding the Power of Expert Systems in Marketing," Journal of Advertising Research, 6, 64-71.
Lazarsfeld, P.E. (1944), "The Controversy Over Detailed Interviews--an Offer for Negotiation," Public Opinion Quarterly, 8, 38-60.
Pratt, D. J., W. Mays, (1989) "Automatic Coding of Transcript Data for a Survey of Recent College Graduates," Proc. of the Section on Survey Methods of American Statistical Association Annual Meeting, 796-801.
Schuman, H., S. Presser (1981), Questions and Answers in Attitude Surveys. New York: Academic Press.
Sheatsley, P.B. (1983) "Questionnaire Construction and Item Writing," in Handbook of Survey Research, P.H. Rossi, J.D. Wright and A.B. Anderson, eds. New York: Academic Press.