Editor’s note: Dr. Steven Struhl is vice president and senior methodologist at Total Research, Chicago. Information on SPSS and SYSTAT can be found at www.spss.com. Information on DBMS/COPY can be found at www.conceptual.com.
Our goal this time around is to extricate some relatively clear statements about data mining and related topics (including “data warehousing” and “knowledge discovery”) from the morass of factoids, non-information and simple errors swarming around these subjects. We also will talk about two new versions of software products (SPSS 10.0 and DBMS/COPY 7.0) that should provide new and useful tools that will help you in mining your data. Finally, we will review the new SYSTAT Version 9.0, which - in spite of not having the words “data mining” stamped all over it - provides all you are likely to need for this wonderful activity.
One initial qualification is in order here. This discussion started with every intention of appearing levelheaded, rational and to the point. However, in revisiting my notes and experiences connected with data mining, just the smallest measure of sarcasm seemed to keep introducing itself, more or less unwanted. So, if you find anything here that seems needlessly unkind or bruises one of your favorite ideas, you can put that down to typographical errors or gremlins, whichever you prefer. If you find anything amusing as we review a subject that sometimes can make your feet fall asleep in sheer excitement, then that’s what we meant to do in the first place.
What does data mining mean?
In search of a good definition, we seemed doomed to start our discussion with a disappointment. A careful review of an extensive literature on the subject - and even more effluvia - leads to one inescapable conclusion: We can say little definitive about what data mining means, aside from the fact that we all are supposed to understand it in depth, and that we all should be able to do it immediately.
Perhaps this lack of clarity arises because data mining has attracted wide attention, going far beyond the community of the unfortunate souls who actually get their hands dirty with data. Now we see increasing interest among, and pronouncements by, several groups with whom many of us have had only sporadic dealings.
Perhaps the most numerous group comprises the various IT folks. (IT refers to “information technology,” not to whatever the actress Clara Bow was supposed to have in the 1920s.) IT people are a considerable force, including hardware mavens, networking experts, and (as expected) Internet gurus. All of them, especially the last group, tend to spew a great deal of “material” (for lack of a better term), whether in print or on the Internet.
Trailing along with them are legions of software vendors, all of whom apparently are salivating at the prospect of selling plenty of “enterprise class” applications for data mining. As a reminder, “enterprise class” software is a special industry code-phrase for something costing between 10 times and one million times whatever you pay for mere desktop software.
Finally, data mining seems to have poked through to, and garnered some attention in, that misty higher plane called top management. While we usually do not encounter too much clarity from those quarters, this makes one fact clear: Data mining has become something big.
Non-useful definitions
You can find non-useful definitions of data mining nearly everywhere you look. Perhaps the champion for brevity among them is this: data mining “uses statistical algorithms to discover patterns in data.” (Source left anonymous as a charitable act.)
Most other expert sources consider the situation carefully, and then make sure to add that data mining discovers “useful patterns” in data. This is bound to be a relief to all of you who thought that data mining intended to capture useless patterns.
Slightly more useful definitions
To sound somewhat fair, we should add that most (but not all) experts agree that data mining involves large amounts of data. For instance, we can find this definition prominently displayed on the SPSS Web site: “Data mining is a ‘knowledge discovery process of extracting previously unknown, actionable information from very large databases.’” Credit for this goes to Aaron Zomes of the META Group. Now, the META Group most likely is a wonderful outfit filled with terrific people - and Mr. Zomes a very bright fellow, kind to his pets, and so on - but their definition raises more questions than it answers. For instance, they talk about extracting “previously unknown information,” but is this in opposition to data that are (already) known? Also, they specifically identify these data as “actionable,” but does this imply that other methods look for data that are pointless?
Also, as we will see shortly, all experts do not agree “knowledge discovery” and “data mining” are strictly synonymous. In fact, when we look carefully at the META Group’s definition, it more or less comes down to doing something useful with a lot of data.
The META Group is far from alone in saying more than they mean. For instance, take this definition: “Data mining is the process of discovering meaningful new correlations, patterns and trends by sifting through large amounts of data stored in repositories, using pattern recognition technologies as well as statistical and mathematical techniques.” (This comes from the Gartner Group, with no specific perpetrator identified.)
Aside from the fact that the Gartner Group uses, employs, or utilizes, terms that are largely synonymous, and also mean mostly the same thing - and so tend to be redundant, if not repetitive - what have they added to the earlier definition? As your reviewer reads it: not much, if anything, (and little, if nothing, in the bargain).
So we sadly must conclude that, even with fusillades of redundant verbiage flying, little of meaning seems to be striking any target. So far, we have established that data mining is something you do with data, and (according to most) with a lot of data.
Also implicit in most definitions is the idea that data mining investigates data sets gathered for some other reason than data analysis. In other words, data mining typically attempts to investigate some historical record (whether a snapshot of one time period, or more) that most likely has not been structured by systematic variations of the factors studied, or experiments.
However, none of the above rules out mining a large database constructed of many surveys, which could arguably be considered a series of experiments. However, even in this case, it seems that the purpose for mining would be to look for effects that extended beyond, or outside, the explicit design of each survey. It seems fairly certain, then, that all data mining involves some post hoc, or retrospective, examination of a body of data in search of “patterns” or “useful information.” This description may seem slender at the moment, but as we shall discuss later, it may have some significance.
That’s nice, but is there any method specific to data mining?
If this discussion has not already stirred the wrath of any expert who has gotten this far, then this section may well do so. Whether you believe data mining uses or requires any special techniques seems to depend on two factors:
1. Whose sales presentation you listened to most recently.
2. How much you know about data analysis.
For instance, if you do not have that much familiarity with data analysis, and you listen to a sales pitch from a company selling neural networks as the answer to data mining, you well could believe that neural networks are essential. Similarly, if the nice people at your friendly statistical software company paid a visit to say, your chief IT person, then your IT person might come to you spouting about how you need the brand new $150,000 “enterprise strength” data mining product from the same company. (Your chief IT person may be even more enthusiastic if he/she/it thinks “a mode” means pie with ice cream on top, and that a “standard deviation” will get you six months in the state penitentiary.)
I suppose many of you have deduced the main point of this section by now. Data mining involves absolutely no techniques that you do not already use for regular data analysis. All the methods that data analysts have used and tried for years still hold -- all the way from simple correlations to the most abstruse reaches of (for instance) hierarchical Bayesian analysis. The same rules governing the use and abuse of these analytical tools still hold also, just as they always have with sample-based data.
What differs about data mining is that you may - for now - need some special software or special hardware if you intend to manipulate everything in huge databases. You can run across databases that weigh in at several terabytes now. As a reminder, a terabyte is 1,000 gigabytes, and as a further reminder, your PC probably holds between three and 40 gigabytes of information on its hard drives, depending on its age and how much you shelled out for it. At one time, everything on the Internet (or at least the portion most of us use, the World Wide Web) consisted of something measurable in mere terabytes. Now, a single Web site, if popular enough, can generate terabytes of data, all of it just waiting to be mined.
I suppose in a few years we will look back at the notion of a few terabytes being an overwhelming parcel of information as old-fashioned and amusing. Before too long, we all should have the power to pick up and handle as much data as we can find anywhere. Then we finally will need to confront the question of what it makes sense to analyze. This appears to be something the data mining community apparently has not yet considered.
What’s most foolish about data mining?
One of the most irksome ideas implicit in data mining is the unstated assumption that, if you somehow handle every piece of data you can, this will improve your analysis. Your reviewer, after noticing this implicit idea, considered it in his usual temperate fashion. The result: more fighting words. The notion that manipulating tons of data will make you smarter is no more than rank nonsense.
The chief proponents of this idea seem to be people with no understanding of sampling or statistical methods. It is the kind of activity that would never be countenanced with a physical endeavor, where wastefulness has a significant cost. For instance, let’s look at the example of real (mineral) mining. In spite of all the tremendously powerful equipment available, nobody does real mining by tearing an entire mountain (or region, or county) to bits, and then sifting through the debris. Rather, sophisticated miners do careful testing of selected regions, find promising areas, and then dig further. They use specialized tools and methods to determine the possible worth of an area before setting up the heavy excavation equipment, and constantly monitor yields to see if they are still following a worthwhile lead.
Of course, you could find a few isolated idiots calling themselves “miners,” armed with little more than pickaxes and dynamite, who will slowly reduce a mountain to rubble, or themselves to exhaustion - or both - without ever knowing how to find whatever they are looking for. One unfortunate aspect of data mining is that the white-collar kinsmen of these foolish souls easily can get their hands onto the analytical equivalent of the largest earth-moving machinery, and start reducing huge masses of data into rubble.
As the many market researchers and statisticians among our readers doubtless realize, intelligent sampling can produce highly reliable and verifiable results without requiring the time and expense of sifting through incredibly large volumes of data. With the rise of enormous databases, “sampling” can take on a different sense than the one we associate with surveys. Using a sample of a mere 10,000 observations, any sample percentage will be accurate within ± 1.4 points. With samples of several hundred thousand, error becomes negligible.
Why bother with huge masses of data, then?
This impulse to tackle all the data seems linked to some other poor ideas (or errors) that apparently still linger around the periphery of data mining. The first of these is that if you get enough data, and a powerful enough piece of software, then data mining will more or less take care of itself. That is, if you simply push a button, then the nice powerful machine will offer you automated insights.
In part, this hunger for automated insights could arise from the fact that many enthusiasts for mining data might not know what they are seeking from the data. They may well be hoping secretly that something the machine throws at them will give them some ideas. We will have more on this later. Before that, though, let us go to the second big, bad idea that seems to hide in the shadows around data mining camps.
This second assumption is perhaps the worst of all. It is the notion that there is not much to data mining, that it just involves poking around a little into the data, and perhaps setting up some automated reports. This is a manifestation of what your reviewer likes to call the CEO factor. That is, people who have been carefully insulated from real data sets for most of their careers now find that they are sitting on massive piles of this mysterious stuff, and that others around them are making a big fuss about doing something with these. Most of these people have never had the unsettling experience of opening up a typical large data set and finding it unwieldy, intractable, and filled with gaps, errors, and garbage. Nearly none of them, I would suspect, ever needed to wrestle one of these monsters to the ground - or even to convince interested onlookers that he or she had done so.
A very clever fellow (Weiler) proposed a rule that seems to describe situations like these well. Namely: “All things are easy for the person who does not have to do them.” To this, I would like to add what I am modestly labeling “Struhl’s Corollary”:
“All things are simple for the person who has absolutely no understanding of how they get done.”
In your author’s experience (which extends over many more large heaps of data than he wishes to recall), any massive database takes plenty of work to analyze effectively. As databases get bigger, it takes more effort just to get them into shape for analysis. The larger the database, the more work you need to do. The relationship may not be strictly linear, but it’s there. Huge databases require plenty of skilled effort to yield anything of strategic or tactical worth. This does not seem likely to change in the near future.
Those who doubt this can try this simple experiment. Go to the amazon.com Web site, and place about 100 orders for books and other paraphernalia that you like. Now, once you have done this, look at the personalized recommendations that the amazon.com computer has served up for you.
If you don’t have the devotion to truth - or to accumulating “stuff” - that this experiment requires, then you possibly could take the word of one who has. Their recommendations still have not hit the target with anything both new and interesting. (As the old joke goes, what’s interesting is not new, and what’s new is not interesting.) I suppose the moral of this is that the machine still has not yet managed to fool one observer into believing he is getting personal attention - from a person.
Some of you may recall that Alan Turing, a large name in artificial intelligence circles, made a prediction (c. 1950) that machines routinely would be fooling us in this way as we crossed the end of century. So far, for your author, artificial intelligence of this type remains clearly artificial. Perhaps others among you have had different experiences that you would like to share.
Some speculations on data mining’s rise as a hot topic
Speaking of Web sites, I (at least) see a direct connection between the rise of data mining and corporations’ eagerness to rush onto the Web. This may seem quite odd at first, but if you stay with me for a few paragraphs I will try to explain.
Whatever logic there is in this linkage runs something like the following. The Web obviously is “the place to be” now. Corporate leaders and other important types can be observed palpably suffering from “Web envy” if they cannot say that they have a killer Web site. The problem with this, though, is that a good proportion of companies with Web sites are still trying to figure out why they have them (except, of course, for the reason just mentioned).
These reasons often prove elusive and not measurable against objective criteria. Figuring out what matters to people on the Web never is simple. For instance, you would imagine that determining the performance of one set of Web sites, those of the on-line merchants, would be fairly easy. After all, they (presumably) all want to sell us things. However, in the strange world of the Internet, even is this is not so. Rarely do you see any discussion of that old basic of financial analysis, the P/E ratio, with Internet businesses. That is because this ratio compares “price” with “earnings,” and the second of these is still largely a fictional entity with most Internet businesses. Instead, we see something new, called a P/R ratio, which compares “price” and “revenue.” (Revenue, of course, is defined as cash inflow before the expenses that erase all “earnings” for most Internet companies.) In your writer’s opinion, the P/R ratio may in fact be a direct measure of how much PR a site is generating.
The question of what a Web site means (or does) becomes more difficult for those many organizations that do not have anything that they can sell effectively on the Web. Yet the sites are there, they all are supposed to make their originators rich and famous, and they are costing their hosts money. I also would speculate that the average corporate Web site costs far more and absorbs far more company resources than its sponsors ever intended.
Now, what is one thing that these Web sites generate? The answer: data. Therefore, if you spend a lot of money on a Web site, and you get back a lot of data, then there really ought to be something in there. Once you discover that you in fact have more data than you imagined possible, perhaps the conviction becomes stronger. There is so much of this stuff that there must be something good in it somewhere.
I am not sure what else can explain some expectations I’ve heard for mining Web site data. For instance, if you proposed to retailers that they gather as much information as possible about all the drivers of all the cars that park in the lot where their stores are situated, you likely would not be spending much more time in their presence (as measured in milliseconds). Yet very similar individuals with Web-site businesses will want to gather the entire “click stream” of every entity that crosses into their cyber-territory, and anything they can find about where these lucky souls have been and are going.
Strangely, the very same people who seem most eager to mine their data (and especially Web data) too often fall silent when asked about the strategic or tactical uses of the data that they hope to gather. You also may have noticed that the definitions of data mining that we reviewed, like most others I have encountered, do not mention using data mining to investigate questions related to the organization’s strategy (and/or tactics). So far, then, the questions remaining largely absent from discussions of data mining are the ones that good data analysts learn to ask first:
- What are your goals (strategies, tactics) and how does this data analysis relate to it?
- What will change as a result of doing this analysis? What type of information do you need to affect what you are now doing, and what kinds of changes are you considering?
Focusing on questions like these is you best chance to make data mining something more than flailing around in the dark under a mountain of data.
A possible taxonomy for data mining and related tasks
So far our discussion has shown us that data mining typically is described as involving large masses of data, and that these data usually are retrospective and not developed as a result of systematic experimentation. We also mentioned that strategic and tactical concerns have been strangely absent in many discussions of this topic.
Perhaps we can come to a better understanding of exactly what data mining comprises by comparing it to other types of data analysis. In this section, we will start with an arrangement proposed by SPSS, Inc., then move on to a somewhat modified view that your reviewer proposes.
 |
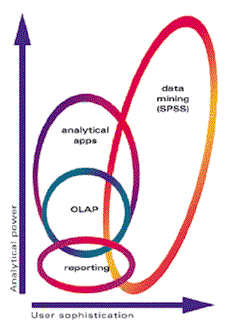
In SPSS’ arrangement (Fig. 1a), which puts “analytical power” on one axis and “user sophistication” on the other, reporting is the most basic function. Another way to say this is that you do not need to know a great deal to run most reporting systems, but you also should not expect to get very much out of them. As the term reporting is used here, most of the output - if not all - falls into a standardized format, and is largely static (or not readily rearranged by the user).
Next in the SPSS hierarchy is something called OLAP. Their chart shows this occupying the same range as reporting for the amount of user sophistication needed, but as capable of providing more analytical “power.” OLAP, as many of us tend to forget, stands for on-line analytical processing.
OLAP, in most cases, provides computer-based (or on-line) reports that users can manipulate, or sometimes look at in varying levels of detail (also known as drilling down). With an OLAP system, for instance, if you find something of interest among the blue-eyed vegetarians from Texas, you may be able to get the system to zoom in to (or drill down into) just that group, and then poke around there. OLAP typically does not allow the user to touch or modify the actual data in any way, but rather just to look at or manipulate many different views of the data.
OLAP also typically lacks many of the features that statisticians find essential for doing intelligent analysis, such as significance testing. Perhaps the theory here is that you should use OLAP only with 100 percent of a large database, and so significance testing then is not an issue. However, without too much effort, you can find OLAP-type reporting of surveys and other sample-based data. These generally look quite impressive, and let users go wild, slicing and dicing results, without giving any hint if observed differences or patterns have any meaning.
You may notice that SPSS divides most of the remaining analytical universe about evenly between analytical apps and data mining. Rightfully, their diagram has both of these extending well beyond OLAP and reporting in analytical power. Also, their chart shows (again quite correctly) that there is some region in which all the varieties of analysis overlap. More controversially, though, they have data mining extending beyond analytical apps in both power and in the sophistication it requires of users. Also, you may notice that the area covered by data mining slants toward the upper right, but that the others do not, which seems to imply that data mining alone has a strong relationship between the user’s sophistication and the power you can find in an analysis. The relationship of data mining to other analytical methods is open to quite a bit of disagreement. Not to disappoint any of you, some will follow.
SPSS gives a specialized meaning to analytical apps, that is, just a relatively narrow set of procedures without the full power of a statistical analysis package like theirs. In your reviewer’s view, this uses a meaning for analytical applications that most users would find somewhat unfamiliar (although correct in certain corners of the industry), as well as not truly contrasting data mining with all data analytical applications. The revised chart proposes to put data mining in that broader context.
 |
In the modified chart (Fig. 1b), we have retained the axes defined by SPSS, but rearranged the two main areas in the chart.
You also will notice an entirely new area on this chart, for knowledge discovery, symbolized by the gold star. Some experts describe knowledge discovery as activities at the upper reaches of data mining. That is, knowledge discovery involves using as many heavyweight methods as needed, and requires both an experienced data analyst and thoughtful effort. In your author’s opinion, it is data mining the way it should get done. (At least you now know why this gets a gold star in the diagram.)
However, those of you whose eyes are still more than halfway open may wonder why stats apps have found their way to the outer reaches of the new diagram, both attaining the highest reaches of analytical power and requiring the most in user sophistication. The reasoning for this is fairly simple. Data mining remains observational, or historically bound. Analytical apps (or applications, as they are known to their less intimate acquaintances) include analyses based on experimental methods. While observation can do many wonderful things, you can reach much further in explanation, prediction, and even “power,” using experimental methods to develop and analyze data.
You may be asking, What is all this about “experiments” supposed to mean? If so, in the broadest terms, you could consider any standardized stimulus presented to a group (or groups), to which the group then returns responses as an experiment. (This also is true even if you were not asking that question.) In short, any reasonable questionnaire could count as an experiment.
In particular, the types of surveys that indisputably are based on experimental methods - such as conjoint analysis and discrete choice modeling (DCM) studies - have long held strong positions as providing terrific analytical or predictive power - and rightly so. It is almost impossible to look at any retrospective view (or simply to trace history) and develop powerful predictions of responses in hundreds or thousands of alternative situations, as is possible with these experimentally based methods.
Even putting methods like conjoint and DCM to one side, nearly all readers should understand that historical patterns in data often show what happened, but fall short on the reasons why things happened. Fortunately for many of us, the need for understanding that goes beyond events promises only to increase. This in turn means that the need will remain for intelligent questions put to various groups or audiences, and for the answers to be interpreted intelligently - no matter how sophisticated the mining equipment becomes.
If fact, it could come to happen, just possibly, that as more data gets mined, the number of unanswered questions will rise. In your writer’s experience, in fact, nearly every long-term expedition into large, uncharted masses of data has brought up more new questions to consider than anybody involved would have imagined at the outset.
Now that we have ensured the continued well-being of the market researchers, statisticians, and data analysts among us, we come to just one more question that frequently arises in connection with data mining.
What is data warehousing, and how does it relate to data mining?
Data warehousing actually is quite complex. It involves taking masses of data, usually data that have lain dormant and inaccessible, and putting them into a reachable and useable form. It may involve gathering all sorts of information from a variety of sources (research, sales, finance, etc.) that routinely have little to do with each other. More than that, it involves putting the data together in ways that work, or in creating the rules that allow users to put together the data they need themselves.
In short, this type of warehousing, properly done, is highly exacting. Because of the many skills involved, an ideal warehouse person likely does not exist. A warehouse team would, it seems, require computer systems experts, at least one very high-powered business reference librarian, and at least one expert on the industry for which the warehousing is being done.
As you likely can see, data warehousing is another of those tremendous misnomers that we encounter all the time. The best data warehouses are more like electronic libraries than anything else, but also dynamic libraries that have linked information, and in which information is maintained and replaced as better data become available. Perhaps “library” has not caught on because it lacks the feel of toughness and macho panache that may be required to sell this concept into certain corporate circles. After all, it’s still perfectly acceptable to have a “warehouse” and feel like you know everything of importance by your gut alone -- and that anything else you might need is incidental and stored someplace in those dusty cartons. If you own a “library,” that could imply it has useful things in it that you in fact do not know already, and worse, need to learn.
What else can we say about data warehousing? Enough to fill at least 100 books, although only four or five of these seem generally regarded as essential reading. Interested readers can write at any time to ask about your writer’s short list -- although most of you who are interested probably have your own list of essential titles. For the rest of us, it’s time to move on to the software.
SPSS 10.0
With version 10.0, the flagship SPSS product splits into two parallel versions. The desktop version remains largely the same as its version 9.0 predecessor, but with several new procedures and a few strong enhancements to its operations. The new parallel version is called SPSS Server. It presents a truly ingenious solution for analysts who need to mine or otherwise analyze huge databases that will not fit onto a PC. The program allows the PC to reach into data on a large server computer. That is, not only does the data stay on the server computer, but that computer does the heavy computational work required. All the processing tasks, including those that would require large temporary files on the PC, get shifted onto the larger and faster machine. Also, any changes to the data (for instance, recoding of variables, adding cluster memberships, or saving discriminant analysis) also take place on the server - so this appears to be a product to use with some caution. In addition, the data do not have to be converted into SPSS format for analyses to run, and with huge data sets this could itself save considerable time. According to SPSS, you can reach into any SQL database with the SPSS Data Access Pack (which is included with SPSS Server 10.0). As Fig. 2 shows (courtesy of SPSS) you even can run multiple Windows sessions with one large centralized source using this version.
 |
SPSS calls its server version “a truly scalable distributed analysis architecture for an enterprise-wide solution.” As you might expect from this, SPSS Server 10.0 costs 10 times as much as its PC-only counterpart.
New features in SPSS 10
SPSS has always excelled at data manipulation and transformation. However, a few minor annoyances remained in its ability to handle some lower-level data editing tasks. In Version 10, a revised data editor resolves most of these small problems. The program now shows both a data view and a variable view in two tabbed windows. The data view is the spreadsheet-like structure familiar from several past versions of SPSS. The new variable view shows a grid listing all the variables and their characteristics on a grid. This new view can save time for those users who do not care to type in SPSS syntax because it allows entry of data and value labels directly on the grid. Also, it allows you to change variable types and other attributes (length, decimal places, formats) for many variable simultaneously - without driving you back to the syntax reference guide to recall how the more obscure transformations need to be invoked.
With the new editor you also should find it easier to examine and organize data. This editor makes it simple for you to select non-contiguous rows or columns, and to re-order your variables in any way you wish.
Also, you now can make changes to variables with a search-and-replace capability that works throughout the entire contents of the data file, including variable and value labels. This should make it much easier to repair any repeated errors that might somehow have crept into labeling, and really shows its value where this happens in files with many variables.
Another enhancement to the program’s overall capabilities is that it can export models to the XML format. This is “extensible markup language,” an enhancement of the HTML language that most of us are meaning to learn really well any day now. Of course, you or some very lucky subordinate of yours will now need to master XML to get the most out of using it to make reports, and it will need to settle into a 100 percent-reliable standard (which it may or may not be at the moment) - but whenever both of these happen, SPSS will be ready for you.
New features in the add-on modules
As a reminder, SPSS has long followed the practice of selling a “base” package along with add-on modules. Over the years, the base package has expanded. Now, in addition to data management, data manipulation, output handling, graphing, and basic analytical procedures (like descriptive statistics, frequencies, correlations, crosstabulations, and non-parametric tests), it includes linear regression, curve fitting, discriminant analysis, factor analysis and principal component analysis. Add-on modules provide more advanced capabilities and cost extra.
SPSS has continually added more advanced and esoteric features with each release, and has a number of new procedures in Version 10. What SPSS now calls the Advanced Models module (formerly Advanced Statistics) now includes the ability to do ranked multinomial logit models in a procedure called polytomous logit universal models (or PLUM). This allows you to analyze a dependent variable that is ordinal or ranked (for instance, one coded as low, medium and high).
PLUM should not be confused, though, with the multinomial logit procedure, which remains in the Regression Models module (formerly called Professional Statistics). This remains a moderately powerful tool for analyzing multinomial logit problems (such as discrete choice models) where the responses do not have any rank information. While this module allows you great flexibility in model specification, it does not have quite the power of the corresponding module in SYSTAT (as we will discuss below).
Also new is another procedure with a stylish acronym, nonlinear principal components analysis (CATPCA). This is a rather advanced procedure which you can use to “reduce” data and to reveal relationships among variables, among cases and among variables and cases. This is part of the Categories Module, which - as a reminder - no longer includes conjoint analysis. Conjoint Analysis has had an add-on module of its own since Version 8.
Putting the PC platform Version 10 through some heavy use, including analysis of some very large data sets (about 300MB to 1GB - not “data mine” size, but respectable) has shown it to run smoothly without any discernable problems. About the only small glitch to report is that it insists on having tables in the output pasted into Excel for Office 2000 as “text.” (In earlier versions, the program would paste tables into Excel in something called the BIFF format, which also was the default for Excel.) As with Version 9, if you want the tables to go into Excel format exactly as you see them in the SPSS output viewer, export them in HTML format, and then use Excel to open them in that format. Once the file is open in Excel, you then can edit or manipulate it just as you can any other spreadsheet. Especially for the Office 2000 version of Excel, HTML is a native language, and the results of opening a file exported from SPSS in HTML format are extremely appealing.
Finally, if it is not clear already, I should note that I have not tested or experimented with the Server version of this program. SPSS long has been among the most reliable of all software companies in delivering on product promises, and so I am content to take their word that their Server program indeed will run as they have specified. I remain not at all eager to rush from the realm of very large samples, which have served so well on so many occasions, into wrestling with terabytes of information. For those of you who are anxious to plunge into the mine, or the warehouse, and tackle all the data, then SPSS is ready to go with you.
DBMS/COPY Version 7
DBMS/COPY (from Conceptual Software) is one of those rare occurrences in the world of software: a program that sets out to do something useful and does it extremely well. DBMS/COPY is the closest thing your reviewer has yet found to a universal translator for the many file formats in which you may find data. It handles a staggering number of statistical analysis programs, spreadsheets, databases, and other miscellaneous applications, allowing you to send data back and forth between them - and to see and control what you are doing in the bargain. The newest version of DBMS/COPY adds two modules that let you do very quick “on the fly” data analysis, file manipulation and viewing. I have worked with several earlier versions of DBMS/COPY and always have found this a program that inspires both confidence and enthusiasm.
DBMS/COPY has many outstanding features. One that is likely to be of interest to many users is that it provides the best means available for getting data into and out of SAS from other statistical packages. This means, for instance, that if you own SPSS and want to analyze a dataset that comes only in SAS format, DBMS/COPY will let you translate and use the whole thing, variable and value labels included. Similarly, should you belong to the brotherhood of loyal SAS users and need to send a file in non-SAS format to some heathen not using SAS, you now can do so with a minimum of effort.
Also, you most likely will find the “spreadsheet grabber” in DBMS/COPY superior to the options available in other programs, since it allows you to select exactly the ranges you want for data and labels, and to choose from any page in a multi-page workbook. Again, you get to see the data in the workbook as you choose it, and can either enter the ranges by typing them in, or by highlighting them with the mouse. The program is smart enough to translate the verbose labels you are likely to find in spreadsheets into the required format for statistics programs like SPSS (short variable names accompanied by long descriptive labels).
If you are going from a program that has value labels, like SPSS, to one that does not (like Excel), DBMS/COPY can create new variables for the destination program that hold the value labels, while retaining the variables for the original values.
DBMS/COPY always has been a standout with ASCII files, with an excellent facility that allows you to see the data’s record structure, and read in files with many lines or records per individual. It now has added intelligence for handling “free format” files, where data items do not reside in fixed locations, but rather run to whatever length needed and are separated by spaces. DBMS/COPY will scan free format ASCII files, and determine both variable types and their maximum lengths.
The DBMS/Analyst module that now comes with DBMS/COPY offers a powerful system with programming features that can manipulate multiple databases. In addition to handling more than one input database, it allows you to split that data into multiple output databases, write reports, read complex text files, do array processing, sort, transpose data, tabulate data, generate summary statistics and calculate regressions. It has a powerful “macro scripting” language, that seems easy to master. It easily can convert multiple files from one format to another.
Even SAS users will feel at home with DBMS/Analyst. It has modules equivalent to the data step, sort, freq, means, summary, univariate, tabulate, transpose and print procedures in SAS.
The program now includes another module called DBMS/Explorer. While this does not promise to lift, parse and slice terabytes of data, its makers have clearly identified it as a data mining tool. In any event, it is an interactive, fast and easy to use tool for data exploration. Because of its speed, DBMS/Explorer makes it simple for you to dig into the data, developing multiple views of its structure, including the ability to drill down into specific data subsets. DBMS/Explorer also can provide useful preprocessing for your data, for instance, doing rapid “value mapping,” or taking raw data values and combining them into more useful groups with more understandable names. For instance, if you wanted to do a demographic study of different age brackets but had too many values, you could use DBMS/Explorer interactively to create the precise groups you need.
In short, this is another excellent release of an outstanding piece of software. As you deal with more data from more different sources, you should find DBMS/COPY increasingly valuable.
SYSTAT 9.0
SYSTAT started quite a number of years ago as a competitor to SPSS in the PC-based data analysis market. Now SYSTAT is offered by SPSS, but is positioned mostly as a scientific product. However, you may well find that if your analytical requirements are extensive, you will need both of these products. Although they both cover all the basics, SPSS and SYSTAT seem complementary to each other, rather than competitive - as mentioned in some earlier reviews.
Each program has its own strengths, and SYSTAT has many different procedures and approaches to procedures that you cannot find in SPSS. Even where the programs overlap, you may find that the features or approaches in SYSTAT have something new and useful to offer.
In particular, as mentioned above, SYSTAT has an outstanding multinomial logit module which allows you to do the most sophisticated types of choice-based models. For instance, with SYSTAT, you can model in “cross-effects” (not to be confused with interactions), which some of the experts say you absolutely must have to create fully realistic models of marketplace choices. (If you feel like you are eavesdropping on a conversation in another language here, cross-effects are needed in choice-based models - or discrete choice modeling, or DCM - to overcome various complaints about assumptions that underlie these models. If you have set up the choice-based survey correctly, the net effects of these assumptions turn out to be small in many cases. However, using cross-effects in the models we construct helps us all feel better at night, knowing we did not miss anything important. Building DCM models is a topic that could take up an entire article - or perhaps even a book - elsewhere. So perhaps we can content ourselves at this moment with the recognition that cross-effects are good, and SYSTAT allows you to use them.)
SYSTAT offers everything in one program, with no add-on modules required. Its list of features is truly impressive. Looking at some of the broad areas we find the following:
- excellent data management on par with that available from SPSS;
- a very powerful output manager, using the same basic “tree and viewer window” structure that you find in SPSS, which allows you to move quickly to any part of your output, rearrange the output, and so on;
- customizable toolbars;
- bootstrapping of errors for nearly all procedures;
- a wide range of descriptive statistics, including “stem and leaf” displays;
- a wide range of ANOVA methods, including MANOVA and ANCOVA;
- classification and regression trees;
- a wide range of cluster analysis procedures;
- conjoint analysis (although this is a more generalized and likely less familiar variant than the SPSS version, which does not seamlessly generate conjoint designs and “cards” and take you through the analysis);
- correspondence analysis;
- design of experiments, including advanced methods with a wizard that helps set up the experiment;
- discriminant analysis;
- factor analysis;
- general linear models;
- logistic regression (binary, multinomial, discrete choice and conditional);
- loglinear models;
- missing value analysis;
- multidimensional scaling;
- nonlinear regression;
- path analysis (the RAMONA procedure);
- partially ordered sets (POSAC);
- perceptual mapping;
- probit;
- set and canonical correlations;
- signal detection analysis;
- smooth module, with 126 non-parametric smoothers, including LOESS;
- survival analysis;
- test item analysis;
- time series;
- two-stage least squares.
Beyond this impressive list of capabilities, SYSTAT continues its tradition of offering an exceptional variety and range of graphs and charts. The program could indeed live up to its claim that it “offers more scientific and technical graphs than any other desktop statistics package.” I cannot claim to have reviewed every statistical package, but SYSTAT certainly offers more scientific and technical graphs than any other desktop statistics package. If you want some very esoteric types of charts - such as Chernoff faces, Fourier blobs, multiplots, kernel densities, or Voronoi tessellations - then SYSTAT will not disappoint you. If you are wondering what all those terms were supposed to mean, we have provided a picture of SYSTAT’s chart output (courtesy of SYSTAT), that may give you an idea of some of the incredible ways in which this program can display patterns in data.
 |
As you may see in Figure 3, SYSTAT maintains a stronger link to its command-line-based past than does SPSS. The program starts by default with a window open in which initiates can immediately enter typed commands. However, all the important functions in the program now also run from menus. In its overall look and feel, the program is fairly similar to SPSS. If you are trying to use this program for the first time, as with any highly complex and powerful piece of software, you should expect at least a little bit of learning time.
SYSTAT may require a look at the manuals every now and then, but probably not many for anyone with at least a little familiarity with a statistics program. On the positive side, you might not mind reading the manuals with SYSTAT. They are surprisingly well-written, to the point, and have a lot of useful information about the analytical methods. In particular, the manuals’ sections on charting and graphing show great thoughtfulness, and are worth reading for their own sake. It’s rare that you can say that about anything in a statistics manual.
As a reminder, SYSTAT does not offer a server version like SPSS, so you cannot use it to reach into and push around an asteroid-sized mass of data on a server. However, if you can get a very large sample from that server, then SYSTAT will provide you with as many analytical methods as you can find in any PC-based statistics program. In short, SYSTAT provides all the tools you would ever need to mine every recognizable fragment from your data.
The part you have been waiting to read
Now we have arrived at the conclusion of the article, with the hopes that several important lessons have become clear. More or less in the order presented, here they are.
- It’s possible (and perhaps mandatory) to say a lot about data mining without imparting too much meaning.
- Data mining is a pretty ripe target for various denigrating comments. (Perhaps we could even pull out an old quote from Don Marquis and say that it’s more than ripe, it’s rotten.) By the way, as we rush to press, none other than Dilbert has launched a set of cartoons lambasting data mining. (Your author cleverly neglected to get permission to use these nearly ideal illustrations for this article.)
- You do not need to feel intimidated about data mining. It’s entirely the same old analytical procedures you know - it’s all things that you already can do. Much of it, in fact, is being done at a more rudimentary level than you would imagine possible. Its practitioners range all the way down to hardware-expert types who are busy posting articles with catchy titles like, “It’s good to know your customer.”
- The idea that you need to analyze every piece of data in a database, rather than using a very large sample, is both foolish and wasteful. Nonetheless, all the signs point toward our needing to start slinging the terabytes fairly soon, because some people will never get the idea that this is not necessary.
- It’s time for the data analytical community (and especially the market researchers) to stake their claim in this territory, instead of leaving the mine to all those other people who don’t know nearly as much about what they are doing.
As far as the software goes, here are the main points.
If you need to tear into all the data, look into SPSS 10 Server. At some $10,000 (or $9,995, as SPSS will have it), it costs 10 times as much as the regular SPSS base, but it certainly is a lot less expensive and more efficient than buying your own server computer on which to house and analyze a huge database.
- Even if you do not have a terabyte to tackle yet, SPSS 10 is a worthy upgrade over Version 9. The improvements to the data editor alone are worth the price of moving to the new version.
- If you need to translate files back and forth between many data sources, and want to see and know what you are doing in the process, DBMS/COPY Version 7 is an excellent piece of software, continuing this program’s long history as an outstanding utility. The new version adds impressive data handling and exploring capabilities to the program.
- If you want an incredibly comprehensive package of statistical methods all in one program - no add-on modules required - then SYSTAT could well be the program for you. SYSTAT remains one of the leading programs for analyzing choice-based modeling (or DCM), providing many of the important tools that the “real professionals” like to use.
As always, we welcome your comments or suggestions. Compliments or questions can be sent directly to the e-mail address shown in the editor’s note at the beginning of the article. You will also find the Web addresses for the suppliers of the software listed there. These sites most likely will answer questions, and certainly have plenty more information about the products, and even allow you to order them on-line if you wish. Note though, that if you are planning to buy the SPSS base and several modules, you may be able to get a package price if you call them to discuss what you need. Finally, please put any complaints in a stamped, self-addressed envelope (SASE). Make sure the envelope is sealed and that you include the correct postage before mailing. Then watch your mailbox carefully.